|
Pattern Name: GeometricDecomposition
|
AlgorithmStructure Design Space
|
This pattern is used when (1) the concurrency is based on
parallel updates of chunks of a decomposed data structure, and (2)
the update of each chunk requires data from other chunks.
- Domain decomposition.
- Coarse-grained data parallelism.
There are many important problems that are best understood as a
sequence of operations on a core data structure. There may be other
work in the computation, but if you understand how the core data
structures are updated, you have an effective understanding of the
full computation. For these types of problems, it is often the case
that the best way to represent the concurrency is in terms of
decompositions of these core data structures.
The way these data structures are built is fundamental to the
algorithm. If the data structure is recursive, any analysis of the
concurrency must take this recursion into account. For arrays and
other linear data structures, however, we can often reduce the
problem to potentially concurrent components by decomposing the
data structure into contiguous substructures, in a manner analogous
to dividing a geometric region into subregions -- hence the name
GeometricDecomposition. For arrays, this decomposition is along one
or more dimensions, and the resulting subarrays are usually called
blocks. We will use the term "chunks" for the substructures or
subregions, to allow for the possibility of more general data
structures such as graphs. Each element of the global data
structure (each element of the array, for example) then corresponds
to exactly one element of the distributed data structure,
identified by a unique combination of chunk ID and local
position.
This decomposition of data into chunks then implies a
decomposition of the update operation into tasks, where each task
represents the update of one chunk, and the tasks execute
concurrently. We consider two basic forms of update: (1) an update
defined in terms of individual elements of the data structure
(i.e., one that computes new values for each point) and (2)
an update defined in terms of chunks (i.e., one that computes new
values for each chunk).
If the computations are strictly local, i.e., all required
information is within the chunk, the concurrency is "embarrassingly
parallel" and the
EmbarrassinglyParallel pattern should be used. In many cases,
however, the update requires information from points in other
chunks (frequently from what we can call "neighboring chunks" --
chunks containing data that was nearby in the original global data
structure). In these cases, information must be shared between
chunks in order to complete the update.
Motivating examples.
Before going further, it may help to briefly present two
motivating examples: a mesh-computation program to solve a
differential equation and a matrix-multiplication algorithm.
- Mesh-computation program. The first example illustrates
the first class of problems represented by this pattern, those in
which the computation is "by points". The problem is to solve a 1D
differential equation representing heat diffusion:
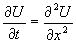
The approach used is to discretize the problem space
(representing U by a 1-dimensional array and computing
values for a sequence of discrete time steps). We will output
values for each time step as they are computed, so we need only
save values for U for two time steps; we will call these
arrays uk (U at the timestep k) and
ukp1 (U at timestep k+1). At each time step, we
then need to compute for each point in array ukp1 the
following:
ukp1(i)=uk(i)+(dt/(dx*dx))*(uk(i+1)-2*uk(i)+uk(i-1))
Variables dt and dx represent the intervals
between discrete time steps and between discrete points
respectively. (We will not discuss the derivation of the above
formula; it is not relevant to the parallelization aspects of the
problem and so is outside the scope of our pattern language.)
Observe that what is being computed above is a new value for
variable ukp1 at each point, based on data at that point
and its left and right neighbors -- an example of the "update
defined in terms of individual elements of the data structure".
We can create a parallel algorithm for this problem by
decomposing the arrays uk and ukp1 into
contiguous subarrays (the chunks described earlier) and operating
on these chunks concurrently (one task per chunk). We then have a
situation in which some elements can be updated using only data
from within the chunk, while others require data from neighboring
chunks, as illustrated by the following figure (solid boxes
indicate the element being updated, shaded boxes the elements
containing needed data).

- Matrix-multiplication program. The second example, taken
from [Fox88], illustrates the second class of problems, those in
which the computation is "by chunks". The problem is to multiply
two square matrices (i.e., compute C = A · B), and
the approach is to decompose the matrices into square blocks and
operate on blocks rather than on individual elements. If we denote
the (i,j)-th block of C by Cij, then we
can compute a value for this block in a manner analogous to the way
in which we compute values for new elements in the standard
definition of matrix multiplication:
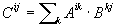
We can readily compute this using a loop like that used to
compute each element in the standard matrix multiplication; at each
step we compute the matrix product Aik ·
Bkj and add it to the running matrix sum. This gives
us a computation in the form described by our pattern -- one in
which the algorithm is based on decomposing the data structure into
chunks (square blocks here) and operating on those chunks
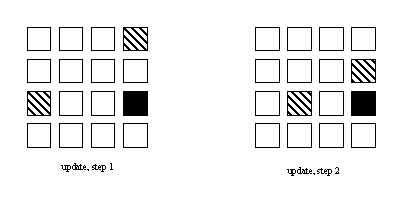
concurrently. If we decompose all three matrices into square blocks
(with each task "owning" corresponding blocks of A,
B, and C), the following figure illustrates the updates
at two representative steps (again solid boxes indicate the "chunk"
being updated, and shaded boxes indicate the chunks containing data
needed for the update).
These two examples illustrate the two basic categories of
algorithms addressed by the GeometricDecomposition pattern. In both
cases, the data structures (two 1D arrays in the first example,
three 2D matrices in the second) are decomposed into contiguous
subarrays as illustrated.
More about data structures.
Before turning our attention to how we can schedule the tasks
implied by our data decomposition, we comment on one further
characteristic of algorithms using this pattern: For various
reasons including algorithmic simplicity and program efficiency
(particularly for distributed memory), it is often useful to define
for each chunk a data structure that provides space for both the
chunk's data and for duplicates of whatever non-local data is
required to update the data within the chunk. For example, if the
data structure is an array and the update is a grid operation (in
which values at each point are updated using values from nearby
points), it is common to surround the data structure for the block
with a "ghost boundary" to contain duplicates of data at the
boundaries of neighboring blocks.
Thus, each element of the global data structure can correspond
to more than one element of the distributed data structure, but
these multiple elements consist of one "primary" copy (that will be
updated directly) associated with an "owner chunk" and zero or more
"shadow" copies (that will be updated with values computed as part
of the computation on the owner chunk).
In the case of our mesh-computation example above, each of the
subarrays would be extended by one cell on each side. These extra
cells would be used as shadow copies of the cells on the boundaries
of the chunks. The following figure illustrates this scheme: The
shaded cells are the shadow copies (with arrows pointing from their
corresponding primary copies).
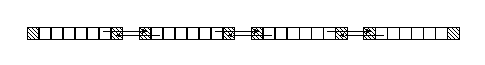
Updating the data structures.
Updating the data structure is then done by executing the
corresponding tasks (each responsible for the update of one chunk
of the data structures) concurrently. Recalling that the update for
each chunk requires data from other chunks ("non-local data"), we
see that at some point each task must obtain data from other tasks.
This involves an exchange of information among tasks, which is
often (but not always) carried out before beginning the computation
of new values.
Such an exchange can be expensive: For a distributed-memory
implementation, it may require not only message-passing but also
packing the shared information into a message; for a shared-memory
implementation it may require synchronization (with the consequent
overhead) to ensure that the information is shared correctly.
Sophisticated algorithms may schedule this exchange in a way that
permits overlap of computation and communication.
Balancing the exchange of information between chunks and the
update computation within each chunk is potentially difficult. The
goal is to structure the concurrent algorithm so that the
computation time dominates the overall running time of the program.
Much of what is discussed in this pattern is driven by the need to
effectively reach that goal.
Mapping the data decomposition to UEs.
The final step in designing a parallel algorithm for a problem
that fits this pattern is deciding how to map the collection of
tasks (each corresponding to the update of one chunk) to units of execution (UEs). Each
UE can then be said to "own" a collection of chunks and the data
they contain.
Observe that we thus have a two-tiered scheme for distributing
data among UEs: partitioning the data into chunks, and then
assigning these chunks to UEs. This scheme is flexible enough to
represent a variety of popular schemes for distributing data among
UEs:
- Block distributions (of which row distributions and column
distributions are simply extreme cases) are readily represented by
assigning one chunk to each UE.
- Cyclic and block-cyclic distributions are represented by making
the individual chunks small (perhaps as small as a single row or
column, or even a single element) and assigning more than one chunk
to each UE, with the mapping of chunks to UEs done in a cyclic
fashion. Cyclic distributions can be effective in situations where
simpler block distributions would lead to poor load balance.
Use the GeometricDecomposition pattern when:
- Your problem requires updates of a large non-recursive data
structure.
- The data structure (region) can be decomposed into chunks
(subregions), such that updating each chunk can be done primarily
with data from the same chunk.
- The amount of computation required for the update within each
chunk is large enough to compensate for the cost of obtaining any
data required from other chunks.
In many cases in which the GeometricDecomposition decomposition
pattern is applicable, the data to share between UEs is restricted
to the boundaries of the chunks associated with a UE. In other
words, the amount of information to share between UEs scales with
the "surface area" of the chunks. Since the computation scales with
the number of points within a chunk, it scales as the "volume" of
the regions. This "surface-to-volume effect" gives these algorithms
attractive scalable execution behavior. By increasing the size of
the problem for a fixed number of UEs, this surface-to-volume
effect leads to favorable scaling behavior, making this class of
algorithms very attractive for parallel computing.
More formally, this pattern is applicable when the computation
involves:
- A potentially-large non-recursive data structure that either
(1) consists of a collection of points (a "region") and a set of
variables, such that each point is represented by a set of values
for the variables (a simple example being a multi-dimensional
array), or (2) can be decomposed into substructures (e.g., in the
case of an array, partitioned into blocks) in a way that is
algorithmically useful (e.g., the desired computation can be
expressed in terms of operations on the blocks).
- A sequence of update operations on that data structure, where
an update operation takes one of two forms: (1) assigning, for
every point in the region, new values for one or more of the
variables, or (2) assigning, for every substructure, new values for
its variables. The update operation must be one that can be
parallelized effectively, as described subsequently.
To see which operations can be parallelized effectively, we need
to look at what data is read and written during the course of the
update operation, focusing on two questions:
- Locality considerations: Is the data needed to update
point p (or chunk c) local to p (c), or
does it correspond to some other point (chunk)? The less data from
other points (chunks) required for the update, the more likely it
is that the parallelization will be effective.
- Timing considerations: Is the data needed to update
point p (or chunk c) available at the beginning of
the update operation, or will it be generated in the course of the
update? Conversely, does the update for point p (chunk
c) affect data that must be read during the update of other
points (chunks)? If all the needed data is present at the beginning
of the update operation, and if none of this data is modified
during the course of the update, parallelization is easier and more
likely to be efficient.
With respect to the latter question, the simplest situation is
that the set of variables modified during the update is disjoint
from the set of variables whose values must be read during the
update (as is the case in the two motivating examples presented
earlier). In this situation, it is not difficult to see that we can
perform the updates in any order we choose, including concurrently;
this is the basis for the correctness of this parallelization
scheme. It is easy to see that in this situation we can obtain
correct results by separating each task into two phases, a
communication phase (in which tasks exchange data such that after
the exchange each task has copies of any non-local data it will
need) and a computation phase.
Implementations of this pattern include the following key
elements:
- A way of partitioning the global data structure into
substructures or "chunks" (decomposition).
- A way of ensuring that each task has access to all the data it
needs to perform the update operation for its chunk, including data
in chunks corresponding to other tasks.
- A definition of the update operation, whether by points or by
chunks.
- A way of assigning the chunks among UEs (distribution) -- i.e.,
a way of scheduling the corresponding tasks.
This pattern can be used to provide the high-level structure for
an application (that is, the application is structured as an
instance of this pattern). More typically, an application is
structured as a sequential composition of instances of this pattern
(and possibly other patterns such as
EmbarrassinglyParallel and
SeparableDependencies), as in the examples in the Examples
section.
- The programmer must explicitly manage load balancing. When the
data structures are uniform and the processing elements (PEs) of the
parallel system are homogeneous, this load balancing can be done
once at the beginning of the computation. If the data structure is
non-uniform and changing, the programmer will have to explicitly
change the decomposition as the computation progresses in order to
balance the load between PEs.
- The sizes of the chunks, or the mapping of chunks to UEs, must
be such that the time needed to update the chunks owned by each UE
is much greater than the time needed to exchange information among
UEs. This requirement tends to favor using large chunks. Large
chunks, however, make it more difficult to achieve good load
balance. These competing forces can make it difficult to select an
optimum size for a chunk.
- How the chunks are mapped onto UEs can also have a major impact
on the efficiency of these problems. For example, consider a linear
algebra problem in which elements of the matrix are successively
eliminated as the computation proceeds. Early in the computation,
all of the rows and columns of the matrix have numerous elements to
work on, and decompositions based on assigning full rows or columns
to UEs are effective. Later in the computation, however, rows or
columns become sparse, the work per row or column becomes uneven,
and the computational load becomes poorly balanced between UEs. The
solution is to decompose the problem into many more chunks than
there are UEs and to scatter them among the UEs (e.g., with a
cyclic or block-cyclic distribution). Then as a chunk becomes
sparse, there are other non-sparse chunks for any given UE to work
on, and the load remains well balanced.
Key elements.
Data decomposition.
Implementing the data-decomposition aspect of the pattern
typically requires modifications in how the data structure is
represented by the program; choosing a good representation can
simplify the program. For example, if the data structure is an
array and the update operation is a simple mesh calculation (in
which each point is updated using data from neighboring points),
and the implementation needs to execute in a distributed-memory
environment, then typically each chunk is represented by an array
big enough to hold the chunk plus shadow copies of array elements
owned by neighboring chunks. (The elements intended to hold these
shadow copies form a so-called "ghost boundary" around the local
data, as shown in the figure under "More about data structures"
earlier.)
The exchange operation.
A key factor in using this pattern correctly is ensuring that
non-local data required for the update operation is obtained before
it is needed. There are many ways to do this, and the choice of
method can greatly affect program performance. If all the data
needed is present before the beginning of the update operation, the
simplest approach is to perform the entire exchange before
beginning the update, storing the required non-local data in a
local data structure designed for that purpose (for example, the
ghost boundary in a mesh computation). This approach is relatively
straightforward to implement using either copying or
message-passing.
More sophisticated approaches, in which the exchange and update
operations are intertwined, are possible but more difficult to
implement. Such approaches are necessary if some data needed for
the update is not initially available, and may improve performance
in other cases as well.
Overlapping computation and computation can be a straightforward
addition to the basic pattern. For example, in our standard example
of a finite difference computation, the exchange of ghost cells can
be started, the update of the interior region can be computed, and
then the boundary layer (the values that depend on the ghost cells)
can be updated. In many cases, there will be no advantage to this
division of labor, but on systems that let communication and
computation occur in parallel, the saving can be significant. This
is such a common feature of parallel algorithms that standard
communication APIs (such as MPI) include whole classes of
message-passing routines to support this type of overlap.
The update operation.
If the required exchange of information has been performed
before beginning the update operation, the update itself is usually
straightforward to implement -- it is essentially identical to the
analogous update in an equivalent sequential program (i.e., a
sequential program to solve the same problem), particularly if good
choices have been made about how to represent non-local data. For
an update defined in terms of points, each task must update all the
points in the corresponding chunk, point by point; for an update
defined in terms of chunks, each task must update its chunk.
Data distribution / task scheduling.
In the simplest case, each task can be assigned to a separate
UE; then all tasks can execute concurrently, and the intertask
coordination needed to implement the exchange operation is
straightforward.
If multiple tasks are assigned to each UE, some care must be
taken to avoid deadlock. An approach that will work in some
situations is for each UE to cycle among its tasks, switching from
one task to the next when it encounters a "blocking" coordination
event. Another, perhaps simpler, approach is to redefine the tasks
in such a way that they can be mapped one-to-one onto UEs, with
each of these redefined tasks being responsible for the update of
all the chunks assigned to that UE.
Correctness considerations.
- The primary issue in ensuring program correctness is making
sure the program has the correct values for any non-local data
before using it. In simple instances of this pattern (in which all
non-local data is available at the start of the computation), this
is easily guaranteed by structuring the program as a sequential
composition of two phases, an exchange-information phase in which
data is copied among UEs and a local-computation phase in which all
the UEs compute new values for their chunks using the just-copied
data.
- Optimizations such as avoiding copying (for shared memory or
when each UE has multiple chunks) and overlapping communication
with computation can improve efficiency but make it more difficult
to be confident that indeed the correct values for non-local data
are being used.
Efficiency considerations.
- Decisions about how to decompose and distribute the data affect
efficiency not only by influencing the ratio of computation to
coordination (which should be as large as possible) but also by
influencing load balance. Large chunks can make it easier to
achieve a high ratio of computation to coordination but can make it
more difficult to achieve good load balance.
- Efficiency will likely be improved if communication can be
overlapped with computation, although this likely requires a more
sophisticated and hence more potentially error-prone program.
- Efficiency can also be greatly affected by the details of the
implementation of the exchange operation, so it is helpful to seek
out an optimized implementation, which for many applications is
likely to be found in one of the collective communication routines
of a coordination library (MPI, for example).
Mesh computation.
The problem is as described in the Motivation section.
First, here's a simple sequential version of a program (some
details omitted) that solves this problem:
real uk(1:NX), ukp1(1:NX)
dx = 1.0/NX
dt = 0.5*dx*dx
C-------initialization of uk, ukp1 omitted
do k=1,NSTEPS
do i=2,NX-1
ukp1(i)=uk(i)+(dt/(dx*dx))*(uk(i+1)-2*uk(i)+uk(i-1))
enddo
do i=2,NX-1
uk(i)=ukp1(i)
enddo
print_step(k, uk)
enddo
end
This program combines a top-level sequential control structure
(the time-step loop) with two array-update operations; the first
can be parallelized using the GeometricDecomposition pattern, and
the second can be parallelized using the
EmbarrassinglyParallel pattern. We present two parallel
implementations:
Matrix multiplication.
The problem is as described in the Motivation section.
First, consider a simple sequential program to compute the
desired result, based on decomposing the N by N
matrix into NB*NB square blocks. To keep the notation
relatively simple (though not legal Fortran), we use the notation
block(i,j,X) to denote, on either side of an assignment
statement, the (i,j)-th block of matrix X .
real A(N,N), B(N,N), C(N,N)
C-------loop over all blocks
do i = 1, NB
do j = 1, NB
C-----------compute product for block (i,j) of C
block(i,j,C) = 0.0
do k = 1, NB
block(i,j,C) = block(i,j,C)
$ + matrix_multiply(block(i,k,A), block(k,j,B))
end do
end do
end do
end
We first observe that we could rearrange the loops as follows
without affecting the result of the computation:
real A(N,N), B(N,N), C(N,N)
do i = 1, NB
do j = 1, NB
block(i,j,C) = 0.0
end do
C-------loop over number of elements in sum being computed for each block
do k = 1, NB
C-----------loop over all blocks
do i = 1, NB
do j = 1, NB
C-----------compute increment for block(i,j) of C
block(i,j,C) = block(i,j,C)
$ + matrix_multiply(block(i,k,A), block(k,j,B))
end do
end do
end do
end
We first observe that here again we have a program that combines
a high-level sequential structure (the loop over k) with an
instance of the GeometricDecomposition pattern (the nested loops
over i and j).
Thus, we can produce a parallel version of this program for a
shared-memory environment by parallelizing the inner nested loops
(over i and j), for example with OpenMP loop directives as in the
mesh-computation example.
Producing a parallel version of this program for a
distributed-memory environment is somewhat trickier. The obvious
approach is to try an SPMD-style program with one process for each
of the NB*NB blocks. We could then proceed to write code
for each process as follows:
real A(N/NB,N/NB), B(N/NB,N/NB), C(N/NB,N/NB)
C-------buffers for holding non-local blocks of A, B
real A_buffer(N/NB,N/NB), B_buffer(N/NB,N/NB)
integer i, j
C = 0.0
C-------initialize i, j to be this block's coordinates (not shown)
C-------loop over number of elements in sum being computed for each block
do k = 1, NB
C-----------obtain needed non-local data:
C----------- block(i,k) of A
if (j. eq. k) broadcast_over_row(A)
receive(A_buffer)
C----------- block(k,j) of B
if (i .eq. k) broadcast_over_column(B)
receive(B_buffer)
C-----------compute increment for C
C = C + matrix_multiply(A,B)
end do
end
We presuppose the existence of a library routine
broadcast_over_row() that, called from the process
corresponding to block (i,j), broadcasts to processes corresponding
to blocks (i, y), and an analogous routine
broadcast_over_column()(broadcasting from the process for
block (i,j) to processes for blocks (x,j)).
A cleverer approach, in which the blocks of A and
B circulate among processes, arriving at each process just in
time to be used, is given in [Fox88]. We refer the readers to
[Fox88] for details.
Most problems involving the solution of differential equations
use the geometric decomposition pattern. A finite-differencing
scheme directly maps onto this pattern.
Another class of problems that use this pattern comes from
computational linear algebra. The parallel routines in the
ScaLAPACK library are for the most part based on this pattern.
These two classes of problems cover a major portion of all
parallel applications.
If the update required for each "chunk" can be done without data
from other chunks, then this pattern reduces to the EmbarrassinglyParallel pattern. (As an
example of such a computation, consider computing a 2-dimensional
FFT by first applying a 1-dimensional FFT to each row of the matrix
and then applying a 1-dimensional FFT to each column. Although the
decomposition may appear data-based (by rows / by columns), in fact
the computation consists of two instances of the
EmbarrassinglyParallel pattern.)
If the data structure to be distributed is recursive in nature,
then rather than this pattern the application designer should use
the DivideAndConquer pattern.