ABI. Application binary interface. A program binary coded to an ABI can run on any system that supports that ABI without relinking or recompilation. See API.
Abstraction. A representation of a problem, process, etc., that focuses on logical properties rather than on implementation details.
Abstraction hierarchy. A representation framework proposed by [Rasmussen85] to describe complex work environments. The AH is a multileveled representation format with each level describing the system in terms of a different set of attributes. Higher levels of abstraction represent the system in terms of purposes and functions, whereas lower levels represent the system in terms of physical implementations. In effect, each level of the AH is a different model of the same system. [Bisantz94].
Amdahl's law. Amdahl's law defines the maximum speedup available from an algorithm on a particular system. It holds because parallel algorithms almost always include work that can only take place sequentially. From this sequential fraction, Amdahl's law provides a maximum possible speedup. For example, consider the parallelization of a sequential program. If we define the following variables:
Tseq = time for the sequential program
a = fraction of Tseq that represents inherently sequential operations
g = fraction of Tseq that represents operations that can be done in parallel
P = number of processors
S(P) = maximum speedup using P processors
Smax = maximum possible speedup
P = Number of processors
the best possible speedup for P processors is:
S = 1 / (α + (γ / P))
In the limit of infinite number of processors, this expression becomes:
Smax = 1 / α
AND-parallelism. This term refers to one of the main techniques for introducing parallelism into a logic language. Consider the goal "A: B,C,D ". In AND parallelism, subgoals B, C, and D are executed in parallel. All subgoals are working on the same problem and each must succeed if the goal A is to succeed.
API. Application programming interface. A program coded to an API can be recompiled to run on any system that supports that API. See ABI.
Atomic operation. Operation that executes without interference by other concurrently-executing processes or threads.
Barrier. A synchronization mechanism applied to groups of processes, with the property that no process in the group may pass the barrier until all processes in the group have reached the barrier. In other words, processes arriving at the barrier suspend or block until all processes have arrived; they may then all proceed.
Beacons. Features or details visible in a program or documentation that serve as indicators of the function of the particular operation or structure. [Brooks83] [Detienne90]
Binary semaphore. See semaphore. A binary semaphore is one whose value is constrained to be 0 or 1. This means that not only the P operation but also the V operation can suspend (in the latter case, if initiated when the value of the semaphore is 1).
Bisection bandwidth. The bidirectional capacity of a network between two equal-sized partitions of nodes. The cut across the network is taken at the narrowest point in each bisection.
ccNUMA. Cache-coherent NUMA. A NUMA model where data is coherent at the level of the cache. See NUMA.
Cluster. Commercial definition: A collection of potentially distinct computers that are tightly coupled and share an address space. An example would be several SHV systems connected through SCI. Academic definition: Any collection of distinct computers that are connected and used as a parallel computer. Examples include Ethernet-connected workstation networks and rack-mounted workstations dedicated to parallel computing. See workstation farm and distributed computer.
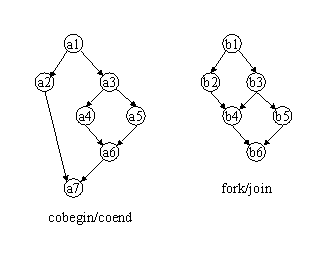
cobegin/coend. These language constructs are used to denote parallel composition of program blocks (e.g., cobegin A // B coend to compose A and B). In parallel composition, the blocks being composed execute in parallel (i.e., concurrently), and the composition as a whole is considered to have terminated when all the blocks have terminated. This might be implemented by having a parent process start a collection of child processes, one for each element of the composition, and then wait for them to terminate. This is not as general as the fork/join case; there are precedence graphs that cannot be represented using cobegin/coend. This is illustrated by the two precedence graphs below; the graph on the left can be implemented with cobegin/coend, while the graph on the right requires the more general fork/join.
Concurrency.
Concurrent execution. We say that two programs are executed concurrently when they are in effect executed simultaneously. This can be accomplished by actually executing them simultaneously, or by interleaving the actions of one with the actions of the other.
Concurrent program. Program with multiple loci of control (threads, processes, etc.). Concurrent programs are typically written for one of two reasons: to improve performance, or to satisfy an inherently concurrent specification.
Condition variable. Condition variables can be considered as part of the monitor synchronization mechanism. A condition variable is used by a process or thread to delay until the monitor's state satisfies some condition; it is also used to awaken a delayed process when the condition becomes true. Associated with each condition variable is a queue of suspended (delayed) processes or threads. Operations on a condition variable include wait (add this process or thread to the queue for this variable) and signal (awaken a process or thread from the queue for this variable). Different implementations of signal are possible; it may be guaranteed to awaken the process at the head of the queue, or it may be simply guaranteed to awaken some process from the queue. See monitor. A good reference is [Andrews91].
Counting semaphore. See semaphores, binary semaphores. Counting semaphores are semaphores that are not binary.
Design pattern. A design pattern is a "solution to a problem in context"; that is, it represents a high-quality solution to a recurring problem in design.
Distributed shared memory. A system that provides the abstraction of shared memory, allowing programmers to write to shared-memory model, even though the underlying hardware uses distributed memory. This can be at the operating system level or at the programming environment level (as with Linda).
DSM. See distributed shared memory.
Efficiency. Efficiency measures how effectively the resources of the multiprocessor system are used. Quantitative definitions of efficiency generally take the form:
e = (Tref / P * Tpar(P))
where P is the number of nodes, Tref is some sequential reference time, and Tpar(P) the parallel time. The most rigorous definition of efficiency sets Tref to the execution time for the best sequential algorithm corresponding to the parallel algorithm under study. When analyzing parallel programs, "best" sequential algorithms are not always available, and it is common to use the runtime for the parallel program on a single node as the reference time. This can inflate the efficiency, since managing the parallel computation always (even when executing on one node) incurs some overhead.
Explicit shared memory. A shared-memory programming model in which processes share a region of memory that is distinct from the processes' local memory. By default, nothing is shared. Access to this memory is usually through explicit statements such as in/out (Linda), get/put (GA), or gather/scatter (DOLIB).
Focal segment. Also known as the focal line. The focal segment is the key code segment that serves to define the function of a plan. (See plan.) It is the driving force of a plan. This is closely related to the idea of the kernel idea in algorithm development. For example, in a sort plan, the line of code that does the pairwise compare is key to defining the plan. See plan.
fork/join. A way of specifying concurrency between processes. When a process executes a fork, it creates an additional process that executes the specified code. Both processes then execute concurrently. When one or more processes execute corresponding joins, they all suspend until all have arrived at the join, after which a single merged process continues. . See cobegin/coend.
Frames. A mechanism of knowledge representation.
Frameworks. A term used by some parallel object-oriented groups (e.g., POET and POOMA) to distinguish their systems from more traditional library- or language-based parallel programming environments. A framework provides an environment that takes care of the top level and provides a frame within which user-modified components can be placed. It usually comes with an assortment of pre-made components to help the user rapidly take advantage of the system. Examples include POET and POOMA, and also TCL/Tk, Smalltalk, and Visual Basic.
Future variable. A term referring to a memory location that will eventually hold the result from a computation. For example, in the Tera programming environment, a future statement creates a new parallel activity and puts its result into a future variable.
Future statement. See future variable.
Heterogeneous. A word describing a system that contains components of more than one kind. A heterogeneous architecture may be one in which some components are processors, and others memories, or it may be one that uses different types of processors together.
Hypercube. A multicomputer in which the nodes are placed at the vertices of a d-dimensional cube. In most cases, a binary hypercube is used in which each node is connected to n others in a hypercube containing 2**n nodes.
Implicitly parallel. Language notations that do not allow the user to explicitly describe which computations are independent and can thus be performed in parallel. For an implicitly parallel language, the compiler must deduce or prove independence in order to make use of parallel hardware. The comparative difficulty of the deduction separates implicitly parallel languages from explicitly parallel ones. Examples include functional and dataflow languages.
Latency. The time taken to service a request (deliver a message, for example, or retrieve information from a file system).. The latency of a message-passing system is the minimum time to deliver a message, even one of zero length that does not have to leave the source processor; the latency of a file system is the time required to decode and execute a null operation.
Lazy evaluation. A scheduling policy under which no calculation is begun until it is certain that its result is needed. This policy contrasts with the eager evaluation used in most programs, but is often used in functional and logic programming.
Load balance. The degree to which work is evenly distributed among available processors. A parallel program executes most quickly when it is perfectly load balanced; that is, when work is divided among processors such that all processors complete their assigned tasks at the same time.
Locality. The degree to which the computations done by a processor depend only on data values held in memory that is close to that processor (in the sense that it is in memory that is least expensive for the processor to access), or the degree to which computations done on a point in some data structure depend only on values near that point. Locality can be measured by the ratio of local to nonlocal data accesses, or by the distribution of distances of, or times taken by, nonlocal accesses.
Mental model. A representation of a problem space that is held inside the head of the problem solver. A good mental model forms an analogue of the real world representation of the problem. In other words, this model should have the same functional nature and structure as the system it models. See [Johnson-Laird83] and [Ormerod90].
MESI. A cache-coherency protocol in which multiple copies of a cache line can live in a system until one of them is written. At that point, the cache lines become invalid. MESI stands for Modify, Exclusive Share, Invalidate; these refer to the names of status bits in the cache controller register.
Monitor. Monitors are a synchronization mechanism based in some sense on data abstraction. A monitor encapsulates the representation of a shared resource and provides operations that are the only way of manipulating it. In other words, a monitor contains variables that represent the state of the resource and procedures that implement operations on the resource; a process or thread can access the monitor's variables only by calling one of its procedures. Mutual exclusion among the procedures of a monitor is guaranteed; execution of different procedures, or two calls to the same procedure, cannot overlap. Conditional synchronization is provided by condition variables (see condition variables). A good reference is [Andrews91].
MPI. Message Passing Interface. A standard message-passing interface adopted by most MPP vendors as well as by the cluster-computing community. The existence of a widely-supported standard enhances program portability; an MPI-based program developed for one platform should also run on any other platform for which an implementation of MPI exists.
MPP. Massively Parallel Processor. A parallel computer that employs a scalable architecture that can scale to hundreds if not thousands of processors. Due to the bandwidth limitations of shared-memory architectures, MPP machines are almost always based on a distributed-memory, message-passing architecture.
Multiprocessor. A parallel computer in which the processors share an address space. This almost always implies physically shared memory. See symmetric multiprocessor. Examples are the parallel servers from SGI.
Multicomputer. A parallel computer based on a distributed-memory, MIMD parallel architecture. The system appears to the user as a single computer. The Paragon is a multicomputer.
Mutex. A Mutual Exclusion lock. A mutex serializes the execution of multiple threads. It is a simple lock, with only the thread that owns the lock being able to release it. Note that if a thread were to attempt to acquire a mutex it already holds, immediate deadlock would result. To prevent this from happening, there is a variation of a mutex called the "non-recursive mutex". This variant form prevents a thread that holds the mutex from reacquiring the mutex without releasing it first. A mutex is an example of a synchronization primitive. Other common synchronization primitives are reader/writer locks, condition variables, and semaphores.
Network. A physical communication medium. Examples include busses, switches, Ethernet, or a mesh.
Nodes. Common term for the components that make up a distributed-memory parallel machine. Each node has its own memory and at least one processor; that is, a node can be a uniprocessor or some type of multiprocessor.
NUMA. Non-Uniform Memory Access. This term is generally used to describe a shared-memory computer containing a hierarchy of memories, with different access times for each level in the hierarchy. The distinguishing feature is that the time required to access memory locations is not uniform; i.e., access times to different locations can be different.
OO Frameworks. See Frameworks
Operating system. A program which acts as an interface between a user of a computer and the computer hardware.
Opportunistic strategies.
OR parallelism. An execution technique in parallel logic languages in which the evaluation of a problem takes place in several ways at the same time. Consider a problem with two clauses A: B,C: A: E,F. Each of the clauses can execute in parallel until one of them succeeds.
Parallel file system. A file system that is visible to any processor in the system and is physically distributed among a number of disks. To be effective, the aggregate throughput for read and write must be scalable.
Parallel program. A concurrent program in which the concurrency is used to reduce the program's runtime.
parbegin/parend. Another name for cobegin/coend.
PE. See processing element.
Petri net. Petri nets were invented by Carl Adam Petri to model concurrent systems and the network protocols used with these systems. The Petri net is a directed bipartite graph with nodes representing either "places" (represented by circles) or "transitions" (represented by rectangles). When all the places with arcs to a transition (its input places) have a token, the transition "fires", removing a token from each input place and adding a token to each place pointed to by the transition (its output places).
Plan. A program or pseudo-code fragment that solves a single, well defined goal. Examples would be a code fragment to sum a series of numbers or code to input words from a file until the end-of-file character is encountered. [Soloway82] [Rist86]. A program as a whole is described in terms of global plans (sometimes called gplans). For example, most programs can be described in terms of the following high-level global plan: Input a set of data, process the data, then output the data.
Precedence graph. A way of representing the order constraints among a collection of statements. The nodes of the graph represent the statements, and there is a directed edge from node A to node B if statement A must be executed before statement B. A precedence graph with a cycle represents a collection of statements that cannot be executed without deadlock.
Process. A collection of resources that enable the execution of program instructions. These resources can include virtual memory, I/O descriptors, a runtime stack, signal handlers, user and group ids, and access control tokens. A more high-level view is that a process is a "heavyweight" unit of execution with its own address space. See unit of execution, thread.
Process migration. Changing the processor responsible for executing a process.
Processing element. A generic term used to reference a hardware element in a parallel computer that executes a stream of instructions. The context defines what unit of hardware is considered a processing element. Consider a cluster of SMP workstations. In some programming environments, each workstation is viewed as executing a single instruction stream; in this case, a processing element is the workstation. A different programming environment running on the same hardware, however, may view each processor of the individual workstations as executing an individual instruction stream; in this case, the processing element is the processor, not the workstation.
Programming environment. We will use this term to indicate a particular choice of programming language and, where applicable, library (supporting parallelism). Examples are HPF, C with MPI, etc.
Production rules. A mechanism to explain how knowledge is organized in cognitive psychology. A production rule is constructed from two propositions joined into a "condition-action" pair. One proposition is the goal, while the other defines the subgoal(s) that must be satisfied. These types of rules are important in many expert systems. [Anderson87] relates these rules to cognitive issues in programming. [Omerod90]
Race condition. A situation in which the final result of operations being executed by two or more units of execution depends on the order in which those UEs execute. For example, if two units of execution A and B are to write different values VA and VB to the same variable, then the final value of the variable is determined by the order in which A and B execute.
Reader/writer locks. These are similar to mutexes and are used when resources protected by the lock are read far more often than they are written. As with the mutex, the reader/writer lock requires that any thread that acquires the lock must also release is. The reader/writer lock differs from the mutex, however, in that it may be held by multiple readers but by only a single writer. This is implemented directly in POSIX through the rwlock_t type. Solaris 2.x has these locks, but POSIX and Win32 threads don't.
RPC. Remote procedure call. Much as its name suggests, this approach to concurrency works as follows: A process requests another process to do work by executing a remote procedure call, using a well-defined interface for the service to be performed. The processor executing the RPC starts a process to service the request, which performs the desired work, returns the result, and terminates. Remote procedure call is a popular model for implementing distributed client-server computing environments. It is an alternative to interprocess communication (IPC) which allows remote systems to execute a set of procedures to share information.
Rules of discourse. Programming conventions about how to use and compose programming plans. For example, a rule might express the convention that a C constant should be in all upper case (I'm not convinced this is a good example). [Soloway84]
Schema. A structure for representing, in memory, generic concepts of a domain. They are used by cognitive psychologists to help explain how knowledge is organized. A schema contains a set of propositions that are organized by their semantic content. The term was originally coined by [Bartlett32]. Schema can be represented in a number of ways. Some examples are frames [Minsky75] from AI and a script [Schank77]. Schemas emphasize the representational aspects of cognition [Omerod90]. [Detienne90]
SCI. Scalable Coherent Interconnect. An IEEE standard that defines the architecture and protocols to support shared-address-space computing over a collection of processors.
Scripts. A representation of a schema in terms of a sequence of abstract actions with slots for specific instances. See [Schank77] and schema. [Omerod90].
Semaphore. A synchronization mechanism based on a "semaphore" abstract data type with the following characteristics. A semaphore has a value that is constrained to be a non-negative integer. The allowable operations on a semaphore are V ("signal") and P ("wait"); both are atomic operations. A V operation increases the value of the semaphore by one. A P operation decreases the value of the semaphore by one, when that can be done without violating the constraint that the value be non-negative (i.e., a P operation that is initiated when the value of the semaphore is 0 suspends until the value becomes positive).
Semantic nets. A mechanism to explain how knowledge is organized in cognitive psychology.
Shared address space. A shared-memory programming model in which all units of execution share a single address space. Loosely, this means that by default, everything is shared. Threads-based models and compiler-driven parallel programming (e.g., SGI) are classic examples of this approach.
Shared memory. A term applied to both hardware and software indicating the presence of a memory region that is shared between system components. For programming environments, the term means that memory is shared between processes or threads. Applied to hardware, it means that the architectural feature tying processors together is shared memory. See shared address space and explicit shared memory.
Shared nothing. A distributed-memory MIMD architecture where nothing other than the local area network is shared between the nodes.
Single-assignment variables. A special kind of variable to which a value can be assigned only once. The variable initially is in an unassigned state. These variables are commonly used with programming environments that employ a dataflow control strategy, with tasks waiting to fire until all input variables have been assigned.
Single system image. A parallel computer for which system services are available to each node and are viewed by that node as a uniform, single system. For example, the Paragon OS provides a single system image.
SMP. Symmetric Multiprocessor. A shared-memory model in which every processor is functionally identical and of equal status. Every processor has equal access to OS services such as interrupts or I/O. A Paragon MP node is not SMP, since only one processor can handle communication. SGI and Sequent computers are SMP architectures.
Speedup. Speedup is a multiplier indicating how many times faster the parallel program is than its sequential counterpart. If Tseq is the time taken by the sequential program (on one node) and T(P) is the time taken by the parallel program on N nodes, speedup S is given by the following.
S = Tseq / T(P)
When the speedup equals the number of nodes in the parallel computer, the speedup is said to be perfectly linear.
SPMD. Single Program Multiple Data. This is the most common way to organize a parallel program, especially on MPP computers. The idea is that a single program is written and loaded onto each node of a parallel computer. Each copy of the single program runs independently (aside from coordination events), so the instruction streams executed on each node can be completely different. The specific path through the code is in part selected by the node ID.
Switch. A component in some parallel systems that ties nodes together. The switch makes point-to-point connections between various input and output ports. While the switch itself is not scalable to arbitrary sizes (as the hardware supporting a mesh-connected or hypercube architecture), architectures using switches can be scalable, since the switches can be cascaded. An example is the Vulcan switch in the IBM SP2.
Synchronization. The act of bringing two or more processes to known points in their execution at the same clock time. There are many ways to manage synchronization. The most basic mechanisms are mutexes, condition variables, read/write mutexes, and semaphores.
Task. This term can have several meanings, depending on context. We will use it to mean a sequence of operations that together make up some logical part of an algorithm or program.
Thread. A fundamental unit of execution on certain computers. In a UNIX context, threads are associated with a process and share the process's environment. This makes the threads lightweight (i.e., a context switch between threads is cheap). A more high-level view is that a thread is a "lightweight" unit of execution that shares an address space with other threads. See unit of execution, process.
UE. See unit of execution.
Unit of execution. Generic term for one of a collection of concurrently-executing entities, usually either processes or threads. See process, thread.
Virtual shared memory. A system that provides a single address space although the hardware uses distributed memory. See distributed shared memory.
Workstation farm. A collection of workstations networked together and used as a compute server. In most cases, this term is synonymous with the academically-accepted definition of cluster.
XDR. eXternal Data Representation. A standard for machine-independent data structures.