|
Pattern Name: DivideAndConquer |
AlgorithmStructure Design Space |
This pattern is used for parallel applications based on the well-known divide-and-conquer strategy; concurrency is obtained by solving concurrently the subproblems into which the strategy splits the problem.
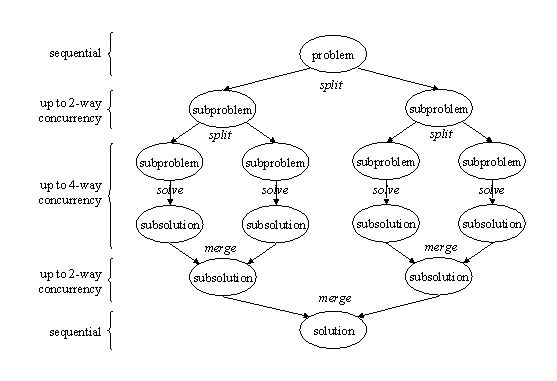
Consider the divide-and-conquer strategy employed in many sequential algorithms. With this strategy, a problem is solved by splitting it into subproblems, solving them independently, and merging their solutions into a solution for the whole problem. The subproblems can be solved directly, or they can in turn be solved using the same divide-and-conquer strategy, leading to an overall recursive program structure. The potential concurrency in this strategy is not hard to see: Since the subproblems are solved independently, their solutions can be computed concurrently, leading to a parallel program that is very similar to its sequential counterpart. The following figure illustrates the strategy and the potential concurrency.
The divide-and-conquer strategy can be more formally described in terms of the following functions (where N is a constant):
The strategy then leads to the following top-level program structure:
Solution solve(Problem P) {
if (baseCase(P))
return baseSolve(P);
else {
Problem subProblems[N];
Solution subSolutions[N];
subProblems = split(P);
for (int i = 0; i < N; i++)
subSolutions[i] = solve(subProblems[i]);
return merge(subSolutions);
}
}
If the subproblems of a given problem can be solved independently, then we can solve them in any order we like, including concurrently. This means that we can produce a parallel application by replacing the for loop in the above program with a parallel-for construct, so that the subproblems will be solved concurrently rather than in sequence. It is worth noting at this point that program correctness is independent of whether the subproblems are solved sequentially or concurrently, so we can even design a hybrid program that sometimes solves them sequentially and sometimes concurrently, based on which approach is likely to be more efficient. This will be discussed further in the Implementation section.
We can map this strategy onto a design in terms of tasks by defining one task for each invocation of the solve function, as illustrated in the following figure (rectangular boxes correspond to tasks):
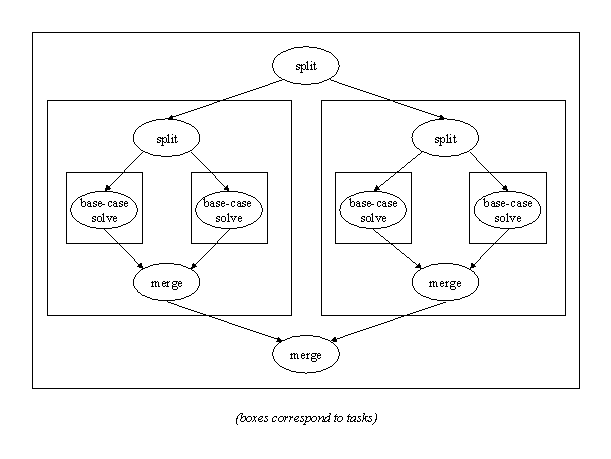
Note the recursive nature of the design, with each task in effect generating and then absorbing a subtask for each subproblem.
Note also that either the split or the merge phase can be essentially absent:
No split phase is needed if all the base-case problems can be derived directly from the whole problem (without recursive splitting). In this case, the overall design will look like the bottom half of our figures.
No merge phase is needed if the problem can be considered solve when all of the base-case problems have been identified and solved. In this case, the overall design will look like the bottom half of our figures.
Use the DivideAndConquer pattern when:
The pattern is particularly effective when:
Implementations of this pattern include the following key elements:
This pattern is typically used to provide high-level structure for an application; that is, the application is typically structured as an instance of this pattern.
It is usually straightforward to produce a program structure that defines the required functions: What is required is almost the same as the equivalent sequential program, except for code to schedule tasks, as described in the next section.
Where a parallel divide-and-conquer program differs from its sequential counterpart is that the parallel version is also responsible for scheduling the tasks in a way that exploits the potential concurrency (subproblems can be solved concurrently) efficiently.
The simplest approach is to simply replace the sequential for loop over subproblems with a parallel-for construct, allowing the corresponding tasks to execute concurrently. (Thus, in the second figure in the Motivation section, the two lower-level splits execute concurrently, the four base-case solves execute concurrently, and the two lower-level merges execute concurrently.) To improve efficiency (as discussed later in "Efficiency considerations"), we can also use a combination of parallel-for constructs and sequential for loops, typically using parallel-for at the top levels of the recursion and sequential for at the more deeply nested levels. In effect, this approach combines parallel divide-and-conquer with sequential divide-and-conquer.
Precondition: baseCase(P) = TRUE .
Postcondition: returned value is a solution of P.
Precondition: baseCase(P) = FALSE .
Postcondition: returned value is an array of N subproblems, each strictly smaller than P, whose solutions can be combined to give a solution of P. Here, "strictly smaller" means smaller with respect to some integer measure that, when small enough, indicates a base-case problem. (This ensures that the recursion is finite.)
Precondition: subS is an array of N solutions such that for some problem P and array of subproblems subP = split(P), subS[i] is a solution of subP[i], for all i from 1 through N.
Postcondition: returned value is a solution of P.
Mergesort is a well-known sorting algorithm based on the divide-and-conquer strategy, applied as follows to sort an array of N elements:
This algorithm is readily parallelized by performing the two recursive mergesorts in parallel. Code for this example may be added later.
[Dongarra87] describes a parallel algorithm for diagonalizing (computing the eigenvectors and eigenvalues of) a symmetric tridiagonal matrix T. The problem is to find a matrix Q such that QT · T · Q is diagonal; the divide-and-conquer strategy goes as follows (omitting the mathematical details):
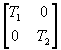
where T1 and T2 are symmetric tridiagonal matrices (which can be diagonalized by recursive calls to the same procedure).
Details can be found in [Dongarra87] or in [Golub89].
Any introductory algorithms text will have many examples of algorithms based on the divide-and-conquer strategy, most of which can be parallelized with this pattern. (As noted in the Consequences section, however, such parallelizations are not always efficient.)
Other uses of this pattern include:
It is interesting to note that just because an algorithm is based on a (sequential) divide-and-conquer strategy does not mean that it must be parallelized with this pattern. A hallmark of this pattern is the recursive arrangement of the tasks, leading to a varying amount of concurrency. Since this can be inefficient, it is often better to rethink the problem such that it can be mapped onto some other pattern, such as GeometricDecomposition or SeparableDependencies.