- (a)
A breadth-first search reaches vertices in order of their distance
from the start vertex.
The code
below uses breadth first search to do the labeling.
public void nearest(int i, int d, int [] reach) { if (d < 0) return; // no vertex is this close ArrayQueue q = new ArrayQueue(); reach[i] = 0; // distance from i is zero q.put(new Integer(i)); while (!q.isEmpty()) { // remove a labeled vertex from the queue int w = ((Integer) q.remove()).intValue(); // mark all unreached vertices adjacent from w // their distance from i is reach[w] + 1 Iterator iw = iterator(w); while (iw.hasNext()) {// visit an adjacent vertex of w int u = ((EdgeNode) iw.next()).vertex; if (reach[u] > d) {// u is an unreached vertex reach[u] = reach[w] + 1; // mark with distance if (reach[u] < d) q.put(new Integer(u)); } } } }
- (b)
-
When adjacency lists are used, the
whileloop takesO(out-degree of w)time for eachwthat is removed from the queue. So the complexity is linear in the number of labeled vertices and the sum of the out-degrees of vertices that are at most distanced-1from vertexi. That is,, the complexity isO(number of vertices that get labeled + sum of out-degrees of labeled vertices excluding those that are distance d).
- (a)
-
Divide the array into three parts: a left part, a middle element,
and a right part.
Check to see if the middle element,
x[middle], is an equilibrium point. If it is, we are done. Ifx[middle] > middle, there is no equilibrium point in the right half of the array. Ifx[middle] < middle, there is no equilibrium point in the left half of the array. The code is given below. This code is similar to that for binary search.
public int equilibriumPoint(int [] x) { int left = 0; int right = x.length - 1; while (left <= right) { int middle = (left + right)/2; if (x[middle] == middle) return middle; if (x[middle] < middle) left = middle + 1; else right = middle - 1; } return -1; // no equilibrium point }
- (b)
-
In each iteration of the
whileloop,right - left + 1is halved. So the code must terminate inO(log x.length)iterations. Each iteration takesO(1)time. So the overall complexity isO(log a.length).
- (a)
-
Kruskal's method considers edges in increasing order of cost.
The first edge considered is
(3,7). It is selected for inclusion into the spanning tree. Next, the edge(1,2)is considered and selected. The edge(3,4)is considered next and selected. The edge(4,7)is considered next. This edge is rejected because its inclusion into the spanning tree results in a cycle. Continuing in this manner, we obtain the spanning tree that is given below.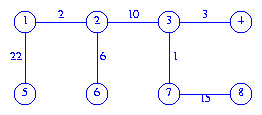
59.
- (b)
-
Prim's method begins with a one vertex tree and grows the tree by adding
an edge and a vertex at each stage until we eventually have a spanning tree.
At each stage, a minimum cost edge is added.
Suppose we begin with vertex
1The edge(1,2)(and hence the vertex2) is added first. Next, the edge(2,6)is added. This is followed by the inclusion of the edge(2,3). Continuing in this manner, we obtain the same spanning tree as was obtained by Kruskal's method. The cost of this spanning tree is59.
- (a)
-
Only the last row of the matrix is useful in constructing the shortest path.
Begin at the destination vertex and use
p[v][6]values to construct the desired path. The result is1,6,3,5,4,2,7. - (b)
-
From the recurrence equations, it follows that
c(i,k,k) = c(i,k,k-1),c(k,j,k) = c(k,j,k-1), and thatc(i,j,k-1)values that are not on row or columnkare used only to computec(i,j,k). Therefore, following iterationkof the outermostforloop,c(i,j) = c(i,j,k). In particular, following the last iteration of the outermost loop,c(i,j) = c(i,j,n).
- (c)
-
Let
hSum(i,j) = sum (from k=i to j) h(k). Forbins(i), i <= n, itemiis at the bottom of a bin. Let itemj, j >= ibe at the top of this bin. This is possible only ifhSum(i,j) + p(i) + p(j) <= h. For an optimal packing, the remaining items (itemsj+1throughn) must be packed using the fewest number of bins (i.e.,bins(j+1)). So we get the following dynamic programming recurrence:
bins(i) =
1 + min{bins(j+1) | hsum(i,j) + p(i) + p(j) <= h and i <= j <= n} - (d)
-
- Step 1
-
Set
q(n+1,j) = 0for1 <= j <= m+1
Setq(i,m+1) = 0for1 <= i <= n
This takesO(n+m)time. - Step 2
-
Compute
q(i,j)fori = n, n-1, ... 1, in that order, using the given equation forq(i,j). For eachi, computeq(i,j)forj = m, m-1, ... 1, in that order. It takesO(mn)time to compute all of theseq(i,j)values.
From the above description and analysis, we see that the overall complexity isO(mn).