PASCAL Programming: § 3: Modular Software Design
In order to produce programs that are readable, reliable, and can be easily
maintained or modified, one must use modular software design. This means
that, instead of having a large collection of statements strung together
in one partition of in-line code, we segment or divide the statements into
logical groups called modules. Each module performs one or two
tasks, then passes control to another module. By breaking up the code into
"bite-sized chunks", so to speak, we are able to better control the flow of
data and control. This is especially true in large software systems.
This section is organized as follows:
3.1. Overview of Modular Software Design
3.2. PASCAL Procedural Organization
3.3. Writing modular code in PASCAL.
3.4. Variables and Datatypes
In Section 3.1, we discuss the basic justification and concepts associated
with software modularity, and show how in-line code can be subdivided to
support modular structure. Sections 3.2 and 3.3 contain a discussion of
the PASCAL PROGRAM and PROCEDURE statements, and
how they support software modularity. In Section 3.4, we show how constructs
called variables can be used to pass information to and from procedures.
(This transfer of information is similar in concept to passing food in and
out of a cafeteria window.)
3.1. Overview of Modular Software Design.
We begin with several definitions (Hint: These may be useful to
learn for a future exam) in support of a brief discussion of software
design goals. We then progress to examples of code segmentation.
- Observation. In the early days of computer programming,
when people coded programs in machine code (ones and
zeroes), it was quite difficult to determine program function
and structure from looking at the code. Humans tend to look
at problems solved on a computer in a linguistic sort of
way, i.e., expect some flow of control or data to be
expressed in the programming language. Ones and zeros don't
tell us much, and they certainly give little indication of
program structure or data/control flow.
Definition. Spaghetti code is the term used for a
computer program that is not well structured and tends to
have highly tangled flows of data and control.
Example. Most assembly language code and machine
code are good examples of spaghetti code. The following
sample of machine code is illustrative:
110101010010001000111001001
010101001000100001011101001
000111001101110001101101010
001111010010010101011001010
001010101111110100101010001
Clearly, there is very little discernable structure in this
type of code.
Definition. In programming languages, the semantic gap
is the difference between the language you use to program the
hardware (machine code) and the language you would like to use
to program the computer as a system. We call the latter, more
abstract language a high-level language or HLL.
Observation. Throughout the history of computing, there have
been at least hundreds of attempts to make computer programming
languages something like English -- easy to read and implicitly
easy to understand. PASCAL is the result of one such effort.
The co-creator of PASCAL, Nicholas Wirth, wanted to have an HLL
that was easy to learn, read, and write. So, he designed PASCAL
around the following concepts:
- PASCAL should close or significantly narrow the
semantic gap.
- Every PASCAL statement should be like a clause
in an English-language sentence.
- The PASCAL program can be thought of as a sentence
in English (namely, a concatenation of clauses).
- Names of procedures, data structures, and variables
in PASCAL should be easily recognizable.
Remark. PASCAL facilitates modular coding via:
- Encapsulating code in PROCEDUREs and FUNCTIONs
that constitute a PROGRAM;
- The use of BEGIN and END statements to define a
functional block of code;
- Strict variable typing (i.e., assigning
datatypes such as integer, real, or
string to variables) in support of parameter
passing between procedures; and
- User-friendly syntax that narrows (but does not
close) the semantic gap.
In the 1960s and 1970s, software designers were faced with large accumulations
of spaghetti code from preceding years. Programs were becoming more complex,
and it was more difficult to keep software running correctly. After trying
various strategies for organizing this morass of code, the following
guidelines for software development emerged:
- Clarity - Code must be easily understandable by humans,
and variable/function names should have obvious meaning.
- Modularity - Programs must be divided into small modules.
- Concision - Modules must perform a few tasks only, using
compact (but not cryptic) notation.
- Reliability - Programs must run correctly, in a repeatable
manner.
- Ease of Maintenance - Software must be easy to maintain and
modify, and must be accompanied by comprehensive documentation.
Clearly written software is often an elusive goal, because technical
programmers tend to prefer cryptic variable names (e.g.,
PR2CD$ instead of clear notation such as
PRICE). Furthermore,
there are many programmers who do not have good writing skills, and
definitely don't enjoy writing documentation. Thus, to be a good
programmer, must concentrate
on improving the quality of your software not only through careful
design and programming, but also through careful documentation.
Modular code is easy to produce from a design, but often hard to
produce from spaghetti code. We discuss this process below, where we
show general examples of code modularization. Modern software development
tools facilitate the generation of modular code, and often check syntax
of programming statements, with some variable type checking possible.
Thus, there exists a variety of evolving techniques for software
design in modular form.
Concisely written code is important to ensuring proper program function.
For example, if your code is so tangled that you can't determine what
it does, how easy will it be for others to understand your work?
It is also important not to create excessively complicated procedures,
which are difficult to debug and maintain, and thus tend to be
unreliable.
Software reliability follows from rigorous software design, checking
one's work, and carefully debugging and testing the software you write
in an incremental fashion. By incremental development, we mean
the construction of a software system and testing of that software on
a piece-by-piece basis. For example, after you write the lowest-level
routines, you should test them all thoroughly before you write the
functions or procedures that call those routines.
Ease of maintenance follows directly from clarity and concision.
For example, if code can be clearly understood, then you or others
would have no trouble understanding and modifying its functionality.
Additionally, concise code is easier to maintain because (a) there
is less code to examine and modify, (b) there is less probability
of making mistakes in modifying the code, and (c) debugging is
easier due to limited scope of functionality.
Now, let's examine some techniques for the conversion of spaghetti code to
modular form.
Spaghetti code is usually written piecewise, in the sense that a programmer
might write Lines 1-50 on Monday, Lines 51-107 on Tuesday, and so
forth. Because humans tend to group their thoughts, there is usually
some locality to the spaghetti code. This means that dataflow
and the flow of control (i.e., statement or expression execution) tend
to cluster in space (i.e., in the code and in memory) and in time.
There exists a class
of computer programs (usually, as part of a suite of software
development tools), called performance analysis software,
dependency checking software, etc. Such programs accept as
input the spaghetti code and produce a calling tree that
illustrates control and data dependencies among modules
in the software system.
For example, consider the spaghetti code shown in Figure 3.1a, where
the tangled lines denote flow of control.
By partitioning the code of Figure 3a into various
modules, each of which execute two or three operations or tasks, it
is possible to produce the modular organization depicted in Figure 3b.

Figure 3.1. General concept of modularizing spaghetti code: (a)
schematic illustration of control transfers (arcs) in spaghetti code;
(b) procedure segmentation according to locaity of control transfer.
A main program that calls three procedures is produced.
A program produced by this method could have a pseudocode
representation similar to the following example:
PROCEDURE P1(< args >):
< procedure definition >
END-PROC
PROCEDURE P2(< args >):
< procedure definition >
END-PROC
PROCEDURE P3(< args >):
< procedure definition >
END-PROC
PROGRAM Main:
< declarations and/or executable code >
P1(< args >) #execute P1
< executable code >
P2(< args >) #execute P2
< executable code >
P3(< args >) #execute P3
< executable code >
END-PROG
which portrays the modularity shown in Figure 3.1b.
There are other methods that can facilitate conversion of spaghetti
code to modularized code, which include:
- Determining the calling hierarchy, which is the
structure defined by the calling sequence of procedures.
For example, in the preceding p-code, we would have the
calling hierarchy
MAIN > (P1 P2 P3). It
is not necessarily easy to determine the calling hierarchy
from spaghetti code, but this information can sometimes be
available from software called an execution profiler.
Such programs keep a record of control flow and can be used
to determine branching and jump behavior (transfers of
control).
- Segmenting code according to functionality, i.e., finding
what function each partition of code performs, then encapsulating
the code into procedures, each of which perform one or two
tasks.
- As a last resort, spaghetti code can simply be chopped into
pieces of more or less equal length. For example, if the p-code
contains assignment statements only, the variables on the
left side of assignment statements would specified as the
output variables of a procedure that contains those
statements. The variables on the right side of the assignment
statements would be specified as input variables.
3.2. PASCAL Procedural Organization.
PASCAL supports hierarchical program structure, in which there is
a high-level procedure, often called the main program or root
procedure. Other procedures are subordinate to the root procedure,
and may call each other, but usually do not call the root procedure. Each
procedure is comprised of statements, which are lines of code
that perform a given function.
The PASCAL language provides three methods for encapsulating code in
procedures. First, the FUNCTION statement specifies a function
that accepts values from its argument list and returns a value or
result through the function name. Second, the PROCEDURE statement
specifies a procedure that accepts values from its argument list and
returns one or more values through its argument list. Third, the PROGRAM
statement allows the programmer to specify high-level source code
that calls predefined procedures to implement a structured
software system. We define these statements as follows:
PROGRAM specification statement:
Purpose: The Program statement specifies the name of a main
program (i.e., the top-level procedure).
Syntax: PROGRAM program-name ( input-file
, output-file ) ; where
Example:
PROGRAM Prog1 (myfile.dat, myfile.rpt); PROGRAM Prog1;
Notes: The input and output file names and their associated
parentheses are optional, and may or may not work with
various operating systems (e.g., DOS, UNIX, etc.)
PASCAL programs have three parts:
- Program and variable specification section;
- Subordinate procedure declarations; and
- Main program executable code.
Pascal procedures and functions are also organized in this way. In this
class, it is strongly recommended that you define all subordinate
procedures at the same level in the main program. Do not encapsulate
procedures within other procedures, but declare them only in the main
program. In other words:
DO THIS NOT THIS
----------------------- ----------------------------
MAIN-PROGRAM MAIN-PROGRAM
Proc #1 specification Proc #1 specification |
<proc-1 code> Proc #2 specification |
Proc #2 specification <proc-2 code> |
<proc-2 code> <proc-1 code> |
Proc #3 specification Proc #3 specification
<proc-3 code> <proc-3 code>
<main-program code> <main-program code>
END. END.
The preceding pseudocode becomes difficult to interpret visually
(and, therefore, difficult to maintain) when Procedure #2 is
defined within Procedure #1. Although this is valid from the
perspective of PASCAL syntax it is not good programming
style, because it decreases readability and, therefore,
increases code maintenance cost.
FUNCTION specification statement:
Purpose: The Function statement specifies the name of a
procedure that inputs values through its argument list and
can be thought of as returning a result through its name.
Syntax: FUNCTION function-name ( argument-1
,..., argument-N ) ; where
Example:
FUNCTION sine(x);
FUNCTION Distance(x,y);
Notes: Do not try to pass output values through the argument
list of a function. This can cause problems in some
PASCAL implementations.
PROCEDURE specification statement:
Purpose: The Procedure statement specifies the name of a
procedure that can input and output values through its
argument list.
Syntax: PROCEDURE proc-name ( argument-1
,..., argument-N ) ; where
Example:
Notes: In the preceding examples, the variable output
was used for passing results to the calling
procedure. In the procedure Smile, there are
no input or output variables declared in the argument
list, but this procedure (and others) may use global
variables, which are discussed in Section 3.4.
BEGIN...END block specification statement:
Purpose: The BEGIN...END statement delimits a block of
compound statements.
Syntax: BEGIN <statements> END where
statements denotes more than one Pascal
statement.
Example:
BEGIN
WRITELN('Hello, world');
WRITELN('Second statement');
WRITELN('Last statement');
END;
Notes: In the preceding example, each statement ends with a
semicolon (;). Since the PASCAL design philosophy views each
statement as a clause, the semicolon punctuation convention
(adopted from English) is employed.
General Comments: Indentation is used to highlight and clarify
program structure. For example, each new level of statements should
be indented two or three spaces to the right. When a block of statements
is closed (e.g., with an END statement), then the indent shifts two or
three spaces to the left. Each statement begins on a new line, except
for multiple short assignment statements that initialize values in a
program.
In the following section, we consider several examples of PASCAL procedural
code.
3.3. Writing Modular Code in PASCAL.
It is not difficult to use PASCAL module specifications to write useful
programs. Here follows a simple example of the FUNCTION construct:
PROGRAM TestFun; {Program specification}
VAR x: integer; {Declare variable x as integer}
FUNCTION Xcubed(x); {Function specification}
BEGIN {Function begins here}
Xcubed := x * x * x; {Function definition}
END; {Function ends here}
BEGIN {Program begins here}
x := 4; {Assign value to x}
WRITELN('x3=', Xcubed(x)); {Print value of x^3}
END. {Program ends here}
In the preceding PASCAL code, note that the VAR statement specifies
a variable of a given datatype. In this case, the variable x is
specified as an integer. Additionally, the WRITELN
statement outputs the legend x3= to the screen, followed by
the value returned by the function call Xcubed(x). If we
preferred not to put the function call in WRITELN's argument list,
we could rewrite the preceding code as:
PROGRAM TestFun; {Program specification}
VAR x,y: integer; {Declare variables x,y as integer}
FUNCTION Xcubed(x); {Function specification}
BEGIN {Function begins here}
Xcubed := x * x * x; {Function definition}
END; {Function ends here}
BEGIN {Program begins here}
x := 4 {Assign value to x}
y := Xcubed(x); {Assign function output to y}
WRITELN('x3=', y); {Print value of y}
END. {Program ends here}
Let us replicate the functionality of the preceding code by using
the PROCEDURE construct and passing the output through a procedural
argument instead of a FUNCTION name, as follows:
PROGRAM TestFun; {Program specification}
VAR x,y: integer; {Declare variables x,y as integer}
PROCEDURE Xcubed(x,y); {Function specification}
BEGIN {Function begins here}
y := x * x * x; {Function definition - y gets x^3}
END; {Function ends here}
BEGIN {Program begins here}
x := 4 {Assign value to x}
Xcubed(x,y); {Procedure call}
WRITELN('x3=', y); {Print value of y = x^3}
END. {Program ends here}
In the preceding programs, the variables x and y have global scope.
That is, their definition as integers held throughout the main program
and called procedures (the function was also a called procedure). In
the following section, we shall see that there is a way to define x and
y that makes procedures and functions reusable. This also facilitates
efficiency and reliability in software development.
3.4. PASCAL Variables and Datatypes.
Programming languages use abstractions called variables to store
values. Because
there are many different types of values (e.g., integer, real, string, etc.),
there exists a method called datatyping by which one such type can
be assigned to each variable. PASCAL supports strict typing, that
is, the datatype is assigned to the variable at compile time and does not
change thereafter.
In PASCAL, valid datatypes that we will consider in this class are:
- Integer - a whole number, such as 1, 2, etc.;
- Real - a decimal number, such as -22.7, 231.8942, etc.;
- Char - a single character, such as 'H' or 'i';
- String - a list of characters, such as 'Hello'; and
- Array - a list of variables, such as (1.1, 2.4,..., 3.7)
or a two-dimensional array. Higher-dimensional structures
are possible.
Most (but not all) compiled languages adopt the strict typing
convention, to simplify compiler design and maintenance. However, there
are some interpreted languages (e.g., SNOBOL) that allow flexible datatyping.
This can produce great difficulty when debugging a program in which a
given variable's value is type-dependent.
In PASCAL, a variable name is any string of valid PASCAL characters.
We recommend that you use the characters {A-Z,a-z,0-9,_} for your
variable names. The following example is illustrative:
VALID NAMES INVALID NAMES
------------------- ------------------
Cost, Price $amount, @price
score score+exam-grade
In each case of invalid names, reserved symbols or characters that
have multiple meanings are used in the name string. This is bad
practice that can lead to compiler errors (i.e., your program
won't compile), or can lead to confusion when debugging or modifying
programs that contain such names.
In PASCAL, variables are typed using the VAR statement,
which is described as follows:
VAR specification statement:
Purpose: The VARiable statement specifies the name and
datatype of procedure or program variables.
Syntax: VAR varname-1,...,varname-N :
datatype ) ; where
Example:
VAR x,y,z : integer;
VAR sum,prod : real;
VAR name,ssn : string;
Notes: It is good programming style to specify only one
datatype in each VAR statement. It is also good
style not to continue VAR statements on multiple
lines. This makes the program easier to read.
We next consider the issue of scope of variables. This
issue is discussed in detail in Chapter 6 of Koffman, the textbook
for this class, from which we condense the following discussion.
Each nested proceudre has its own declaration section and executable
code. The latter is also called the procedure body. This is
also true for main programs. Figure 3.2 illustrates procedure nesting
in a program called Nest. Each rectangle represents a defined
procedure, also called a program block.
A program block contains a program module's formal parameter list,
which is defined by the VAR statement, as well as the declaration
section and procedure body. In Figure 3.2, we illustrate the following
procedure nesting hierarchy:
(Nest > (Outer > Inner, Too))
The statements in each procedure operate only on local variables.
This is good programming practice, and facilitates modularity. If we
were to use global variables, which are declared once at the
beginning of the main program and then hold through all procedures,
this would be bad software engineering practice, because:
- Global variables lead to confusion in debugging, when trying
to trace variable types through many pages of code.
- Global variables are convenient to programmers, but they
do not make procedures re-usable, since there is no variable
declaration at the top of the procedure. In the absence of
proper documentation, one cannot know for sure what datatype
is assigned to a given variable. This adversely impacts the
clarity, reliability, and maintainability of software.
In contrast, local variables are easy to trace, since they are defined
in (and manipulated by) one module only. Since good software
engineering practice dictates that modules be kept small, it is much
easier to trace the flow of data and control in these small modules.
And, the modules can be re-used, because all variable definitions or
declarations are local to the module.
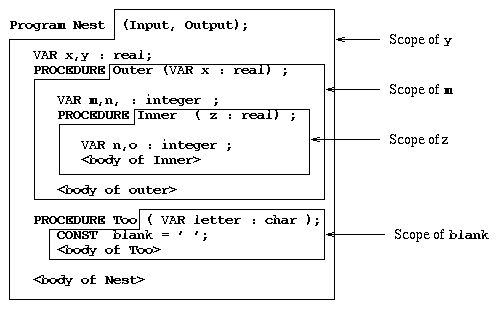
Figure 3.2. Scope of variables in a PASCAL program (after Koffmann, 1992).
Pascal has two rules for determining the scope of variables (area of
influence of a given variable), which are:
- Rule 1. The scope of a variable is the block
in which the variable is declared.
Example. A variable declared as type
T in some procedure P is available within P and all its
subordinate procedures as a variable of type T.
- Rule 2. The redeclaration of a variable v as having type T
within a procedure P holds for P and all its subordinate
procedures, but not for higher-level procedures.
Example. Suppose we have the procedural definition hierarchy
Main > (P1 > (P1a,P1b), P2)). That is, P1 and P2
are defined within Main and P1a and P1b are defined within P1.
If a variable v is declared within Main as a string but
within P1 as real, then v has the type real in
P1, P1a, and P1b. However, v retains the type string
in Main and P2.
Good software engineering practice dictates that all variables be
specified locally in PASCAL, except for Main Program variables, which
are global by default. As noted above, this facilitates modularity
and portability of PASCAL code, and makes debugging much easier.
This concludes our overview of software modularity and PASCAL.
We next discuss PASCAL selection structures.