Reading Assignments and Exercises
This section is organized as follows:
-
6.1. Overview of Memory Hierarchies
6.2. Basics of Cache and Virtual Memory
6.3. Memory Systems Performance Analysis & Metrics
6.4. I/O Devices and Buses
Storage of data in electronic computers has evolved since the beginnings of computer research in the late 1930s. Beginning with latches, relays, and flip-flops, storage progressed to mercury delay lines (an early form of dynamic memory), core memories comprised of magnets threaded on a grid of conducting wires, magnetic drum and disk storage, optical and magneto-optical storage, and faster memory, cache, and registers.
It is natural to group these different types of memory, in particular the memory technologies used today, in terms of storage capacity and speed. This leads us to formulate an abstraction called a memory hierarchy, which we discuss in Section 6.1. Because certain types of memory are faster than others, and since designers place these faster types of memory closer to the processor, it is useful to put smaller amounts of data in the faster memory, which are subsets of larger data stored in slower memory. We call this technique caching (pronounced "cashing"), which is discussed in Section 6.2. The analysis of memory performance is discussed in Section 6.3. We complete the discussion of the five components of a computer with an overview of input and output techniques, protocols, and devices (e.g., buses) in Section 6.4.
Information contained herein was compiled from a variety of text- and Web-based sources, is intended as a teaching aid only (to be used in conjunction with the required text, and is not to be used for any commercial purpose. Particular thanks is given to Dr. Enrique Mafla for his permission to use selected illustrations from his course notes in these Web pages.
6.1. Overview of Memory Hierarchies
Reading Assignments and Exercises
We are concerned with five types of memory:
Registers are the fastest type of memory, which are located internal to a processor. These elements are primarily used for temporary storage of operands, small partitions of memory, etc., and are assumed to be one word (32 bits) in length in the MIPS architecture.
Cache is a very fast type of memory that can be external or internal to a given processor. Cache is used for temporary storage of blocks of data obtained from main memory (read operation) or created by the processor and eventually written to main memory (write operation).
Main Memory is modelled as a large, linear array of storage elements that is partitioned into static and dynamic storage, as discussed in Section 2 of these notes. Main memory is used primarily for storage of data that a program produces during its execution, as well as for instruction storage. However, if main memory is too small for such data, then subsets of the data can be paged to/from disk storage.
Disk Storage is much slower than main memory, but also has much higher capacity than the preceding three types of memory. Because of the relatively long search times, we prefer not to find data primarily in disk storage, but to page the disk data into main memory, where it can be searched much faster.
Archival Storage is offline storage such as a CD-ROM jukebox or (in former years) rooms filled with racks containing magnetic tapes. This type of storage has a very long access time, in comparison with disk storage, and is also designed to be much less volatile than disk data.
The different partitions of the memory hierarchy each have characteristic persistence (volatility). For example, data in registers typically is retained for a period of several cycles to hundreds of cycles, whereas data in cache can persist over tens to thousands of cycles. Data in main memory often remains for as long as the life of a program, and disk storage has persistence ranging from a few milliseconds to years (if the disk is properly maintained). Archival storage lifetime can vary from hours (e.g., incremental backups) to decades (e.g., long-term storage of classified data).
The size of the different memory hierarchy partitions is also an important implementational consideration. For example, register files vary from a few hundred bytes to a few kilobytes, and modern caches from 64KB (embedded processors) to 2MB (large engineering workstations). Main memory ranges from 1MB (embedded processors) to 512MB (desktop computers) to tens of gigabytes (supercomputers). Disk storage ranges from tens to thousands of gigabytes, the latter in the case of disk arrays, whereas archival storage can range as high as hundreds of terabytes for the storage of remote sensing image data.
Access times for registers are on the order of one CPU clock cycle, similar to cache. Main memory takes more time, perhaps several clock cycles to tens of cycles, depending on the disparity between the memory and CPU bandwidths. Disk storage latencies are typically on the order of 5-10 milliseconds, and archival storage (with the exception of CD-ROM jukeboxes) takes minutes to days to access stored data.
Each of these parameters - usage, persistance, size, and access time - are important to the design of storage systems. For example, if small amounts of fast storage are required, then a large register file may be sufficient for compute-intensive but I/O-starved applications. Conversely, I/O-intensive applications could require a large cache and fast main memory with fast virtual memory access to a large disk array.
In the following section, we discuss how properties or attributes of each partition in the memory hierarchy influences the movement of data back and forth between levels of the memory hierarchy. In particular we focus on caching (i.e., movement of data between cache and main memory) and virtual memory (i.e., movement of data between main memory and disk). Here, we use the term data to generalize all bit patterns whether instructions or data.
6.2. Basics of Cache and Virtual Memory (VM)
Reading Assignments and Exercises
It is useful to think of cache as a large read/write buffer for main memory. The purpose of cache is to provide fast access to data stored in main memory, to support I/O operations performed by the processor. For example, this helps speed up I/O-bound applications.
Similarly, virtual memory is a read/write buffer for disk storage. Virtual memory performs the additional function of supporting the illusion of a very large main memory address space, which is usually much larger than a computer's physical memory.
Putting aside the difference between cache and VM (i.e., the emulation of a large address space in VM), let us focus on the similarities between cache and VM. We begin with an event that occurs when data cannot be found in the cache or VM page store, called a cache miss or a page fault.
6.2.1. Cache Misses and VM Page Faults
Assume that we have a cache system and a VM system running side-by-side, for purposes of comparison. The cache contains blocks of data from memory, and the VM contains pages of data from disk. Apart from the fact that cache blocks are usually smaller than memory pages, the concept is the same for cache and VM.
Assume that we want to access a block in cache via a memory operation O. Using an address translation mechanism described in Section 6.2.2, we map the main memory address A to the cache memory address C (where the block of data we want to access is cached). When the processor accesses C using O, it performs a comparison operation to see if the block is really in the cache. If the block is present, this is called a hit, otherwise we have a miss.
Similarly, assume that we want to access a page in virtual memory via an I/O operation I. Using an address translation mechanism described in Section 6.2.2, we map the virtual memory address A to the physical memory address P that references the page store or paging store, where the page of data we want to access is temporarily stored. When the processor accesses P using I, it performs a comparison operation to see if the page is really in the page store. If the page is present, this is called a page hit - otherwise, we have a page fault.
In cache, if the block is not found, then it is retrieved from main memory and stored in the cache. At this point, memory operation O can proceed. Similarly, in VM, if the page is not found in the paging store, then it must be retrieved from disk and written to the paging store before the I/O operation I can be executed.
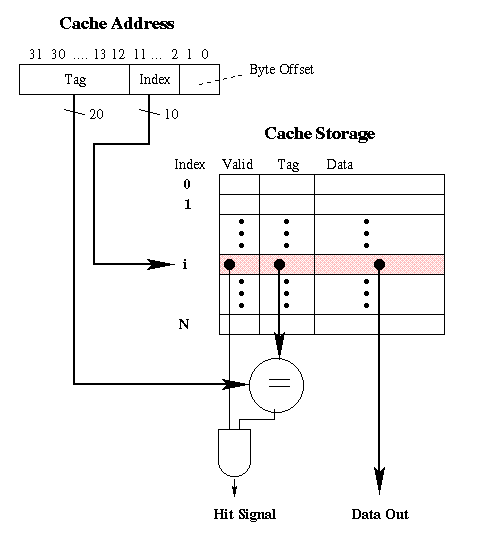
(a)
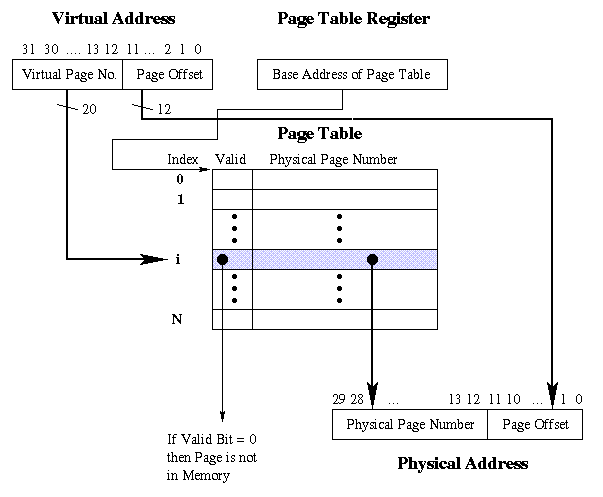
(b)
Figure 6.1. Schematic diagram of (a) cache and
(b) virtual memory, showing the similarities between the two
techniques.
Thus, cache and VM both have similar errors. These misses or page faults adversely impact memory performance at their respective levels of the memory hierarchy, via the following three mechanisms:
Replacement cost - When a cache miss or VM page fault occurs, the processor or memory management unit must (1) find the requested block or page in the lower-level store, (2) write the block or page back to the cache or paging store, and (3) set the appropriate bits (per Section 6.2.5) to reflect the recency of the replacement. These operations incur overhead that would not have occurred if the memory operation had been successful (i.e., if a miss or page fault had not occurred). Of particular interest are the bus and memory costs (discussed below), as well as the block or page replacement strategy. It is crucial that page replacement cause the least possible number of misses or page faults, as discussed in Section 6.2.3.
Bus cost - When a cache block is obtained from memory, it must be transmitted along the bus that connects main memory with the processor or cache (depending on how the physical architecture supports cache). This bus must have very high bandwidth, so as not to impede cache replacement. Similarly, in VM, the bus between the disk and memory must be sufficiently fast not to inhibit data transfer in support of page replacement.
Lower-level storage cost - If a cache miss is encountered, then the requested data must be retrieved from main memory, which implies that main memory itself must be sufficiently fast not to impede overall cache performance for a given average hit frequency. Similarly, in VM, the disk read/write latency must be sufficiently small so as not to slow down the page replacement process.
In order to make memory access efficient under the assumption of cache or virtual memory (or both), we need to correctly design the buffering function implemented in cache or VM by making the computationally intensive parts of the buffering process as efficient as possible. In the next section, we show that the potentially costly operation of address translation can be made efficient via hardware implementation.
6.2.2. Address Translation Mechanisms for Cache and VM
One of the key problems of caching or virtual memory systems is how to translate the virtual address (which the CPU uses) into the corresponding physical address (cache block or page address in the paging store). This can be challenging because of (a) the size of the virtual address space in virtual memory, and (b) temporal inconsistencies between cache and main memory contents, or between paging store and disk contents in VM.
Let us derive an address translation scheme using cache as an example. The cache is a linear array of entries, each entry having the following structure:
Data - The block of data from memory that is stored in a specific entry (also called row) or collection of entries in the cache,
Tag - A small field of length K bits, used for comparison purposes in verifying correct addressing of data, and
Valid Bit - A one-bit field that indicates status of data written into the cache.
Assume that the N-bit virtual address (the address that the processor uses to access cached data) is divided into three fields:
Tag - A K-bit field that corresponds to the K-bit tag field in each cache entry,
Index - An M-bit field in the middle of the virtual address that points to one cache entry, and
Byte Offset - Two bits (in MIPS) that are not used to address data in the cache.
It follows that the length of the virtual address is given by N = K + M + 2 bits.
In order to understand how the cache entries are referenced by the index, we need to observe that there are three ways of arranging data in a cache:
Direct Mapped - There is a one-to-one correspondence between each block of data in the cache and each memory block that we are trying to find. That is, if we are trying to find a memory block b, then there is one and only one place in the cache where b is stored.
Set Associative - Given memory block b that we are trying to find in the cache, there are L entries in the cache that can contain b. We say that this type of cache is called L-way set associative. For example, if L = 2, then we have a two-way set associative cache.
Fully Associative - Any block of memory that we are looking for in the cache can be found in any cache entry - this is the opposite of direct mapping.
It is readily seen that set-associative cache generalizes direct-mapped cache (when L = 1) and fully associative cache (when L equals the number of entries in the cache).
6.2.2.1. Cache Address Translation. As shown in Figure 6.1a, we assume that the cache address (the address used by the processor) has length 32 bits. Here, bits 12-31 are occupied by the Tag field, bits 2-11 contain the Index field, and bits 0,1 contain the Byte Offset information. The index points to the row or entry in cache that supposedly contains the data requested by the processor. We say "supposedly" because the requested data block might or might not be in cache at the location pointed to by the Index.
After the cache row (or rows, in case of L > 1) is retrieved, the Tag field in the cache row(s) is (are) compared with the Tag field in the cache address. If the tags do not match, then a cache miss is detected and the comparator (shown as a circle with an equal sign in Figure 6.1a) outputs a zero value.
Otherwise, the comparator outputs a one, which is and-ed with the valid bit in the cache row pointed to by the Index field of the cache address. If the valid bit is a one, then the Hit signal output from the and gate is a one, and the data in the cached block is sent to the processor. Otherwise, the data is invalid and a cache miss is registered (Hit signal = 0).
6.2.2.2. VM Address Translation. The Virtual Address shown in Figure 6.1b (the address used by the processor) has a Virtual Page Number (VPN), which is similar to the cache address Index field, in that the VPN points to a row in the Page Table (a kind of cache for disk storage). The Valid Bit is then checked - if zero, the page is not in memory, and the page offset must be loaded into the Page Table. Otherwise, the page is in memory, at a location given by the Physical Page Address (PPA).
The PPA is formed by concatenating 1) the Physical Page Number, stored in the Page Table at the location pointed to by the VPN; and 2) the Page Offset, which is the second part of the Virtual Address. The key to improvement of performance in VM is thus efficient transformation of the Virtual Address into the Physical Address.
6.2.2.3. Translation Lookaside Buffer (TLB). The performance of a VM address translation mechanism can be improved by the insertion of a Translation Lookaside Buffer, which exploits the principle of locality. That is, when an address translation is performed, it will probably be required again soon due to spatiotemporal locality of page references. As a result, modern VM systems use an extra piece of hardware that acts a cache for recent translations.
This piece of hardware is the TLB, which holds only page table mappings. Each tag entry in the TLB contains a portion of the VPN, and each data entry of the TLB stores a physical page number. The TLB operates as follows:
If a TLB miss (the requested page exists in memory), then only the address translation is missing from the TLB. This is handled by having the CPU load the translation from the page table into the TLB. The page reference (Step 1) is then tried again.
If a page fault (page not in memory), then this condition is handled by the VM portion of the operating system through a page fault exception produced by the CPU.
Step 1. For every page reference, look up the VPN in the TLB.
Step 2. If a hit results, then the physical page number is used to form the address (per Figure 6.1b), and the corresponding reference bit is turned on. If the processor is performing a memory write, the dirty bit (discussed in Section 6.2.4) is turned on. Control is then passed to Step 1 of this algorithm, where the next page reference is processed.
Step 3. If a miss occurs, determine whether it is a page fault or a TLB (cache) miss, and act accordingly:
This process can be performed either in hardware or software, and there is little performance difference because the basic operations are the same, as discussed below.
Because the TLB is much smaller (has fewer entries) than the page table, the probability of TLB misses is much larger than the probability of page faults. Thus, the cost of TLB misses must be minimized since these are the common case. A TLB miss generally is associated with the following operations:
Retrieve the missing translation from the page table.
Copy the reference and dirty bits for a given TLB entry back to the page table when the TLB entry is replaced. (These bits are the only part of a TLB entry to be modified.) Copying these bits back at miss time is efficient, since the TLB is designed to have a small miss rate.
Some operating systems approximate the reference and dirty bits, thus avoiding writing TLB information except for a new page entry or a miss. A wide variety of associativity is used to make TLBs efficient. For example a small, fully associative TLB has a low miss rate (due to full associativity) and relatively low mapping cost (due to few TLB entries). Conversely, a large TLB would have little or no associativity. The TLB replacement algorithm, which is related to the page replacement algorithm (discussed in Section 6.2.3) must be simple (e.g., random selection) if it is implemented in hardware or software, due to the cost penalty associated with TLB misses.
Reading Assignment. The configuration of a typical TLB is discussed at the bottom of page 580 of the textbook, and the structure and functionality of a real TLB is overviewed on page 583. Know how these TLBs are configured, with justification for selection of each parameter.
6.2.3. Block/Page Replacement Strategies
The replacement problem involves choice of an optimal algorithm that determines what cache blocks or pages to replace with new blocks or pages requested by the processor. This is a nontrivial problem that has been researched over several decades. The optimal algorithm is called random replacement, whereby a location to which a block is to be written in cache is chosen at random from the range of cache indices. In virtual memory, this also applies to pages.
Another strategy is called least recently used (LRU), whereby the page in VM or the cache block that has been accessed least recently is overwritten with the new page or block. This approach, while not always optimal, is intuitively attractive from the perspective of temporal locality. That is, a given program will likely not access a page or block that has not been accessed for some time. However, the LRU replacement strategy does not necessarily work for paging store or cache that is small in relationship to the number of pages or blocks swapped in and out of cache. In such cases, the store or cache is too small to exhibit anything but very short-term locality.
While the random replacement strategy can be implemented using a random number generator (in hardware or software), the LRU replacement algorithm requires that each cache or page table entry have a timestamp. This is a combination of date and time that uniquely identifies the entry as having been written at a particular time. Given a timestamp t with each of N entries, LRU merely finds the minimum of the cached timestamps, as
tmin = min{ti : i = 1..N} .
The cache or page table entry having t = tmin is then overwritten with the new entry.
6.2.4. Write-Through and Write-Back
There are two principal strategies for writing new entries to cache or page table, as follows:
Write-through writes the cache (page table) entry to the cache (resp. page table) as well as to the memory location (resp. disk location) pointed to by the cache (resp. page table) entry being written.
Write-back writes the cache (page table) entry to the cache (resp. page table) only until the current entry is replaced. At replacement time, the final entry is written to the memory location (resp. disk location) pointed to by the cache (resp. page table) entry.
Write-through has the advantage of maintaining temporal consistency of data in cache (page table) and memory (resp. disk), within the time that it takes to write to the backing store. In cache memory systems, this time requirement usually does not represent a significant penalty, since the write-to-memory operation occurs much less frequently than writing to a cache entry. Unfortunately, write-through is not efficient for virtual memory system, due to the much longer latencies required by disk I/O. Write-back is therefore the method of choice for VM systems, and is sometimes used in cache systems.
Reading Assignment. An excellent review of the relative advantages of write-back and write-through is given on p. 607 of the textbook.
Hint: Know these advantages and disadvantages, because you might be asked to discuss them on an exam question.
6.3. Memory Systems Performance Analysis & Metrics
Reading Assignments and Exercises
Now that we have discussed the structure of cache and virtual memory, we are ready to analyze how these systems can be designed to facilitate improved performance. We will see that cache size is determined from a variety of parameters (Section 6.3.1) to facilitate efficient addressing (Section 6.3.2) without compromising cache memory system design (Section 6.3.3). Given these basic concepts and analyses, we focus on improvements to cache performance (Section 6.3.4).
6.3.1. Analysis of Cache Size
It is important to be able to predict cache size from cache design parameters, and vice versa. For example, consider a direct-mapped cache with ND kilobytes (KB) of data, and L words per block, having an M-bit address space. In MIPS, we know that ND/4 words (32 bits per word) are required to store ND KB of data, which implies that the number of blocks NB having L words per block is computed as
NB = ND / (4L) .
Thus, NA = log2(NB) bits are requied to address the cached data. Since we have an M-bit total address to be mapped into the cache, the tag size is given by
NT = M - NA - 2 bits .
Given one valid bit, each cache entry thus has size
NC = 2NA · (32L + M - NA - 2 + 1 ) bits ,
which via substitution of the preceding equations reduces toNC = NB · (32L + M - log(ND) - 2 · log(L) - 1 ) bits .
The following example is illustrative.
Example 1. Let ND = 64 KB, L = 1, and M = 32 bits. From the previous equations, there are 214 words and, since L = 1, there are 214 blocks implying NA = 14 bits. Each block has 32 bits of data plus a tag of length NT = M - NA - 2 = 32 - 14 - 2 = 16 bits, plus a valid bit. The total cache size is thus given by
NC = 214 · (32 + 32 - 14 - 2 + 1) bits = 214 · 49 bits = 784 Kbits .
Now that we know how to compute the size of the address space, let us investigate a technique for locating data in a cache.
6.3.2. Cache Addressing
Suppose we have a cache with NB blocks and a block size of K bytes per block. To what block number does byte address A map? The analytical solution to this problem proceeds stepwise, as follows:
Step 1. The block number B is given by A' mod NB, where A' represents the byte address divided by the number of bytes per block.
Step 2. From the definition of a byte address, and by observing the word offset in MIPS memory, we see that
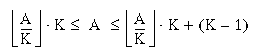 .
.
This defines the range of addresses.
Let us consider the following illustrative example.
Example 2. If NB = 64 blocks and K = 16 bytes, with A = 1200, then
,
which maps to block number 11 = 75 mod 64.
In the following subsection, we will see how memory systems can be designed to efficiently support cache access.
6.3.3. Memory System Design for Cache Implementation
Observe that DRAMs are currently designed with primary emphasis on density (memory capacity, as in Moore's Law), versus minimal access time. Thus, it is difficult in practice to decrease the latency incurred by fetching the first word from memory. (Assuming pipelined memory I/O, we have no such latency for the remaining words in a data stream.) However, we can reduce the I/O cost associated with a cache miss (called the miss penalty) if we increase the memory cache bus bandwidth. This allows larger blocks, but with the same or lower miss penalty as before.
The textbook (pp. 5601-561) shows the following cases for memory design:
Case 1. Memory is one word wide, all accesses are sequential.
Case 2. Memory is NW > 1 word wide, as are the cache blocks and memory-cache bus. A mux is used to move multi-word blocks between cache and CPU.
Case 3. The memory is widened (multiple banks) but not the cache-memory bus.
Let us discuss these cases in the following design example.
Example 3. Let the memory incur time delay tA = 1 cycle to transmit the address, tM = 15 cycles for each DRAM access, and tD = 1 cycle to transmit the data from memory. If the cache in Case 1 has L = 4 words per block and a one-word wide bank of DRAMs, then the miss penalty is given by
Cmiss = tA + L · tM + L · tD = 1 + 4(15) + 4(1) = 65 cycles.
Suppose we double the bus width (e.g., effectively decrease L by a factor of two). Then we have L = 2 and
Cmiss' = tA + L · tM + L · tD = 1 + 2(15) + 2(1) = 33 cycles.
If we use a four-word wide memory, then L = 1 and
Cmiss" = tA + L · tM + L · tD = 1 + 15 + 1 = 17 cycles.
For Cmiss, the number of bytes transferred per miss is given by Nb = 4(4)/Cmiss = 0.25. For Cmiss', Nb = 4(4)/Cmiss' = 0.48, and for Cmiss", Nb = 4(4)/Cmiss" = 0.94.
The major costs to achieve this lower miss penalty are (a) wider CPU-memory bus, (b) potential increase in cache access time due to the mux in Case 2, and (c) extra control logic between the CPU and cache.
6.3.4. Improving Cache Performance
Having found ways to reduce the miss penalty, let us examine techniques for increasing cache performance. Recall the CPU performance equation tCPU = IC · CPI · tclock. Let the product IC · CPI include both CPU cycles and the cycles expended by the CPU while waiting for memory accesses (called memory stall cycles). Thus, we have
tCPU = (CPU-exe-cycles + Memory-stall-cycles) · tclock .
For purposes of simplicity, assume that memory stall cycles arise primarily from cache misses, and are comprised of read and write stalls, as follows:
Memory-stall-cycles = Read-stall-cycles + Write-stall-cycles .
We define the former overhead as
Read-stall-cycles = Read-instructions/program · read-miss-rate · read-miss-penalty .
Write stalls are more complex phenomena, requiring the addition of stalls specific to the write buffer (hardware that helps smooth out the effects of speed differences between cache and memory). Thus, we have
Write-stall-cycles = (Write-instructions/program · read-miss-rate · read-miss-penalty) + Write-buffer-stalls .
Unfortunately, expressions for write-buffer stalls are quite complex in practice. However, with sufficient buffer depth, memory-cache data transfers can proceed (on average) without significant write-buffer stalls, so this effect can be ignored. Write-back schemes also present difficulties due to stalls incurred when writing blocks back to memory. For purposes of simplicity, this effect is not discussed in the notes, but is analyzed in detail in Section 7.5 of the textbook.
In the majority of programs, read and write miss penalties are the same, so we combine the preceding equations to yield
Memory-stall-cycles = Memory-instructions/Program · Misses/instruction · Miss-penalty .
Let us consider an illustrative example.
Example 4. Let a program P have a cache miss rate of 3 percent and a data cache miss rate of 5 percent. if a machine M has a CPI of 2.1 with no memory stalls and a miss penalty of 36 cycles, how much faster would M run if it had a perfect cache (one with no misses)?
Step 1. Assume that the instruction count is denoted by IC, as before. Then, we have
Instruction-miss-cycles = IC · 3 percent · 36 = 1.08 · IC .
Step 2. Let the frequency of loads and stored in Program P be 40 percent of all instructions. Thus, using the preceding equations, we compute the number of memory miss cycles as
Memory-miss-cycles = IC · 40 percent · 5 percent · 36 = 0.72 · IC .
Step 3. From the results of Step 1 and Step 2, and from our preceding discussion of memory stalls, the total number of memory stall cycles is given by 1.08 · IC + 0.72 · IC = 1.8 · IC . This represents a memory stall penalty of more than one cycle per instruction. Thus, the revised CPI that accounts for memory stalls is given by
CPI' = CPI + memory-stall-cycles = 2.1 + 1.8 = 3.9 .
Step 4. From the givens, and from the results of Steps 1-3, above, the performance of the CPU with perfect cache is 2.1 (CPI without cache misses). As we have seen in Steps 1-3, above, the performance of the CPU with realistic cache is given by CPI' = 3.9. Taking the ratio of the CPIs, we find that the performance of the perfect cache can be expressed in terms of a factor f, which is computed as
f = CPI'/CPI = 3.9 / 2 = 1.95 .
This indicates a 95 percent improvement in performance when a perfect cache is used in this instance.
In an interesting application of Ahmdahl's Law, if we increase the processor clock rate, without decreasing the cache miss rate or increasing the memory clock rate, then the performance difference f increases. This effect occurs due to the increasing proportion of memory stalls as a part of total cycles. This is not a fanciful situation, but occurs in practice, for example, when a processor is upgraded without upgrading the cache or memory system correspondingly.
In particular, if a processor designer increases both clock rate and CPI without upgrading memory performance, the following effects occur according to the preceding model:
A lower initial CPI will cause a greater impact due to memory stall cycles; and
The CPU-memory performance gap will likely persist in this situation, even in the presence of hardware upgrades, because (a) main memory performance will probably not improve as fast as CPI cycle time, and (b) memory performance is measured in terms of CPU clock cycles expended by a cache miss. Thus, a higher CPU clock rate induces a higher miss penalty.
It is sometimes tempting to increase the degree of associativity within the cache, the advantage being decreased miss rate. Unfortunately, since all the blocks in a given set must be searched, the hit time increases. Also, the hardware required to compute the match between the cache address tag field and the tags stored in a given set increases linearly with the degree of associativity. Because the miss penalty is program-dependent, it is not possible to exactly predict the effect of increased set associativity. This is further discussed in pp. 568-578 of the textbook.
Similarly, as discussed in pp. 585-594 of the textbook, the effect of page faults in VM can be analyzed using the preceding technique for cache performance analysis. The effect of page faults in VM is much greater, however, due to the large difference between disk access time (milliseconds) and memory access time (nanoseconds).
At a high level, the key concept to remember is the cooperation of cache, main memory, and disk storage to enable VM and cache to work smoothly together as a memory hierarchy. Section 7.5 of the textbook addresses this concept of hierarchical memory in greater detail.
6.4. I/O Devices and Buses
Reading Assignments and Exercises
A processor has little usefulness without the ability to obtain input (read) information from, or produce (write) output to, its external environment, which includes users. I/O devices (Section 6.4.1) mediate data transfer to/from peripheral (non-CPU and non-memory) hardware. We also discuss the procedures, advantages, and disadvantages involved in different methods of I/O device control. Buses (Section 6.4.2) connect peripherals with the CPU or with each other. Bus performance analysis (Section 6.4.3) is key to improving the memory-processor bottleneck, which is often the limiting performance constraint in a computer system.
6.4.1. I/O Devices
Input (output) devices can be thought of as transducers that sense (resp. produce) physical effects and produce (resp. input) machine-tractable data. For example, a computer keyboard (an input device) accepts the physical effect of finger movements and produces a bit sream that the processor, operating system, and application software translates into a byte stream (comprised of characters). Alternatively, a computer monitor (output device) accepts a bit stream generated by a processor and produces a picture on the monitor screen. Some devices mediate both input and output, for example, memory or a disk drive.
The detailed modes of operation of I/O devices are not of interest to this course. Rather, we prefer to focus on the hardware/software interface between I/O devices and CPU (or I/O processor). This topical area merges directly with the discussion of buses in the following section. Salient implementational topics not covered in this course (due to limited time) include SCSI buses and their interface protocols, or high-bandwidth serial versus lower-bandwidth parallel buses for memory-CPU or CPU-peripheral communication.
Another aspect of interest to I/O device management is the technique that the CPU uses to deal with input and output requests. There are three primary methods with which the CPU (or I/O processor) mediates data transfer to/from I/O devices, which are:
Polled I/O, whereby the processor surveys each I/O device in turn to see if the device has output available for the processor, or is able to handle an I/O request.
Interrupt-driven I/O, which is based on the concept of on-demand processing, whereby each I/O device generates an interrupt when an I/O event occurs (e.g., the user presses a key on the computer keyboard). The processor treats these I/O interrupts as discussed previously. For example, in MIPS, the I/O interrupt generates an entry in the EPC and Cause registers, and an interrupt handler transfers control to the appropriate software (utility routine) based on the type of interrupt. After the I/O interrupt is serviced, control returns to the program with which the interrupt was associated, and which is waiting to be executed.
Direct Memory Access (DMA) I/O that transfers data directly from the I/O device to main memory, but requires special hardware. This technique is particularly useful when large amounts of data (e.g., images) must be moved from high-bandwidth devices (e.g., digital video cameras) into memory.
Polled I/O is an orderly technique, easy to use, and requires very little extra hardware. However, it does not necessarily recognize I/O devices that are added after the polling process is intialized. Also, polled I/O can cause starvation if a particular device transfers much data while other devices wait to be polled. If a round-robin polling scheme is used, with a fixed amount of data transferred per device per polling iteration, then this tends to decrease the effective bandwidth for data transfer from/to a particular device.
Interrupt-driven I/O tends to be more disorderly, and can likewise result in starvation if an I/O device can seize the processor while transferring large amounts of data. Interrupt-driven I/O requires the customary interrupt handling software and hardware (e.g., EPC and Cause registers in MIPS). However, I/O interrupts generally yield higher effective bandwidth per device, since time spent polling other devices is not required and thus does not incur overhead.
DMA, while effective for transferring large blocks of data, is not necessarily as effective for numerous small data packet transfers due to the potential overhead of establishing a DMA connection. Additionally, DMA requires supporting hardware such as a DMA controller, DMA memory partition(s), and a fast bus that is often dedicated to DMA.
We next overview buses and their configuration.
6.4.2. Buses
A bus is a collection of one (or more) communication channels, e.g., wires or fiber optic lines, which is used to transmit a serial (resp. parallel) bitstream. In a computer, a bus connects hardware components such as memory, processor, and I/O devices. A bus can have one of the following forms:
Dumb or wire buses simply transmit data without adjustment of bus performance, packetizing of data, etc. This type of bus comprises the majority of board-level and chip-level interconnects in modern computers, for example, CPU-cache interconnection.
Packet buses divide the transmitted data into partitions called packets. Each packet is transmitted along the bus as a contiguous entity. When all packets have been collected at the receiver (also called marshalling), they are re-assembled to reconstruct the original data. Problems with packets include collisions (when two packets try to occupy the same space at the same time), overhead due to large headers or small packet bodies, and erroneous or missing packets due to bus faults. However, packet errors that feature erroneous bits are not limited to packetized data - this effect can happen with any kind of bus.
Reconfigurable buses have the ability to change their connectivity, transmission parameters (e.g., nominal bandwidth), and in some cases monitor data transmission along a bus. In a few very sophisticated implementations, adaptive error detection and correction as well as load balancing schemes can be employed to maintain quality of service within prespecified operational constraints.
Buses have one of two communication modes, as follows:
- Simplex communication is unidirectional (e.g., component
A transmits to component B via the bus, or vice versa). Transmission
from A to B and from B to A does not occur at the same time.
- Duplex transmission is bidirectional (e.g., A-to-B and B-to-A transmission occurs concurrently), for example, by interleaving packets from messages that are sent in alternate directions.
Duplex mode typically has higher error rates than simplex communication mode, due to primarily to collision effects resulting from bidirectional transmission.
6.4.2.1. Realistic Bus Effects. Although bus errors include missing packets, line drops, and bit errors, collision is the principal problem. Here, two packets attempt to occupy the same bus space in the same time increment (e.g., bus clock cycle). Due to these effects, simplex buses typically operate at 70-80 percent of their nominal bandwidth, while duplex buses customarily utilize 30-40 percent of nominal bandwidth.
Example 5. Suppose a bus is rated at a nominal bandwidth B = 1 gigabit per second (Gbps). What is the actual range of useful bus bandwidth in simplex mode, assuming f = 60 percent of packets have to be retransmitted? How many megabytes per second throughput can this realistic bandwidth achieve, absent of overhead?
Answer: If f percent of the packets have to be retransmitted, then the nominal bus bandwidth is decreased by a factor of (1 + f/100). Thus, the effective bandwidth is given by
B' = B / (1 + f/100) = B / (1 + 0.6) = 0.625 · B ,
which corresponds to 625 Mbps. Converting bits to bytes, we obtain 78.125 MB/sec as the actual bus bandwidth.
This is not a fanciful example - the traditional PCI bus has nominal bandwidth of 32 bits parallel at 33 MHz ~ 1 Gbps, while the revised PCI bus design doubles the clock rate to achieve nominal bandwidth of approximately 2 Gbps.
6.4.2.2. Cost of Bus Errors. When a bus error is detected, one or more erroneous (or corrupted) packets must be corrected (where possible) and retransmitted, which incurs the following costs:
CD - cost of error detection procedure (e.g., parity checking, cehcksum formation and comparison);
CC - cost of error correction (where possible); and
CR - cost of packet retransmission.
Assuming that a packet detected as erroneous is corrected or retransmitted, we have the following performance penalty:
Cerr = CD + CC or Cerr = CD + CR .
Further assuming that a fraction f of N packets having Nb bits per packet can be corrected, and a fraction ferr of N packets cannot be corrected and must therefore must be retransmitted, we have the following simplistic modification of the ideal performance equation terr = Nb · N / BWbus:
terr' = N · Nb · (1 + f · (CD + CC) + ferr · (CD + CR))/ BWbus .
Dividing this equation by the preceding equation, we obtain the performance degradation, as follows:
fp = terr' / terr = 1 + f · (CD + CC) + ferr · (CD + CR) .
In practice, CR predominates, so fp ~ 1 + ferr · CR .
Actual models of bus performance are more complex, involving performance of buffers, switches, colision effects, individual bit errors, etc. A discussion of these models is beyond the scope of this course, but an example of a bus performance model is given in [Bhu97], and a fiber optic bus is modelled in [Mat95].
This concludes our discussion of memory and I/O, and ends the summary course notes for CDA3101.