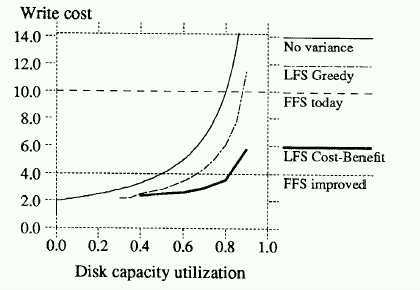
Note that comparison is drawn to FFS write cost of 1992, and a theoretical best possible FFS performance based on estimates by Seltzer, Chen, and Ousterhout.
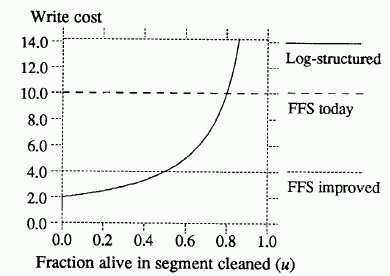
Performance of LogFS as a function of segment utilization (theoretical model).
Each simulated file was 4K bytes in size. In each simulation step one of the files is overwritten with a probability that is uniform in the uniform referencing pattern, and satisfies a 90-10 rule in the hot-and-cold pattern, namely 90% of the files are overwritten 10% of the time. The probability of rewriting was uniform within each of the hotcold groups.
The following figure shows the performance of Sprite LFS after the system has reached capacity and write cost has stabilized. The cleaner used a greedy method, namely, the least used segments were cleaned first.
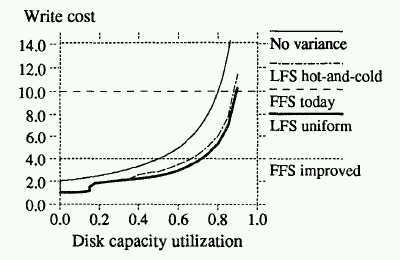
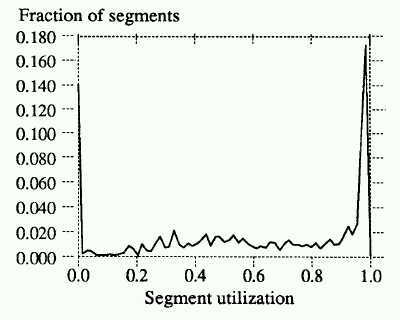
The figure, however, shows the surprising result that the performance under this scenario was worse than under uniform utilization. The reason for this is that the greedy policy means that no cold segments will get cleaned unless they reach extremely low utilization.
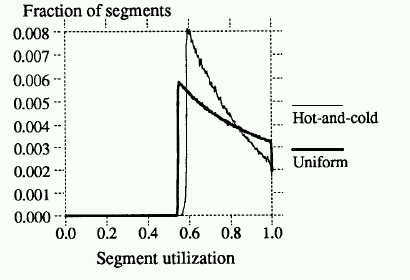
The following figure demonstrates this by showing that in the hot-and-cold simulation, more segments are clustered around the cleaning point than in the uniform simulation. The graph shows the distribution of utilizations in segments available to the cleaner just at the point cleaning will begin.
The benefit-cost ratio they employed is the following:
benefit/cost = free-space-generated*age-of-data/cost
= (1-u)*age/(1+u)
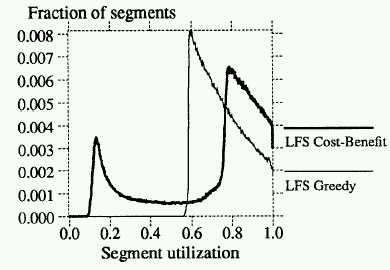
One can see that the performance of the cleaner matches that of predicted FFS best performance at 80% utilization in the cleaned segments.
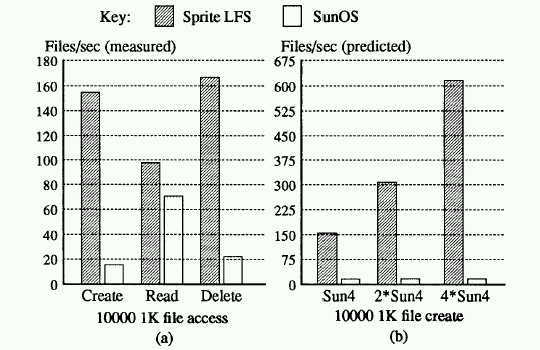
- creates a 100 MByte file with sequential writes,
- reads the file back,
- writes 100MBytes randomly to the existing file,
- reads 100 MBytes randomly from the file, and finally
- reads the file sequentially once more.
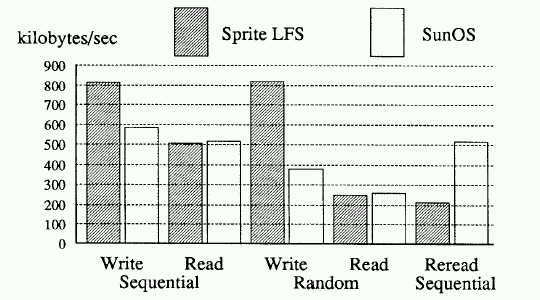
Recall that FFS tries to improve logical locality of single files (under the assumption that reads are generally sequential) at the expense of spending extra time on writes. On the other hand, LFS tries to improve temporal locality of writes (acknowledging that when its time to write, something must be written) at the expense of spending extra time reading data that might be logically sequential in a file.
The graph shows that this improves LFS write performance for all types of access. The performance for random reads or randomly written data and sequential reads of sequentially written data is the same as for FFS. LFS performs more poorly than FFS when rereading randomly written data in a sequential order.