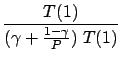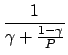![]()
![]()
![]()
![]()
![]()
A B C D E F G H I J L M N O P R S T U V W
![]()
| Abstract data type.
A data type given by its set of allowed values and the available
operations on those values. The values and operations are defined
independently of a particular representation of the values or
implementation of the operations. In a programming language that
directly supports ADTs, the interface of the type reveals the
operations on it, but the implementation is hidden and can (in
principle) be changed without affecting clients that use the type.
The classic example of an ADT is a stack, which is defined by its
operations, typically push and pop. Many
different internal representations are possible.
| |||||||||
| Abstraction.
Abstraction can have several meanings depending on the context. In
software, it often means combining a set of small operations or
data items and giving them a name. For example, control
abstraction takes a group of operations, combines them into a
procedure, and gives the procedure a name. As another example, a
class in object-oriented programming is an abstraction of both
data and control. More generally, an abstraction is a
representation that captures the essential character of an entity
but hides the specific details. Often we will talk about the named
abstraction without concern for the actual details, which may not
be determined.
| |||||||||
| Address space.
The range of memory locations that a process or processor can
access. Depending on context, this could refer to either physical
or virtual memory.
| |||||||||
| ADT. See abstract
data type.
| |||||||||
Amdahl's law.
A law stating that (under certain assumptions) the maximum speedup
that can be obtained by running an algorithm on a system of P
processors is
where
| |||||||||
| AND parallelism.
This is one of the main techniques for introducing parallelism
into a logic language. Consider the goal A:
B,C,D (read ``A follows from B and C and D'') which means
that goal A succeeds if and only if all three subgoals B
and C and D succeed. In AND parallelism,
subgoals B, C, and D are evaluated in
parallel.
| |||||||||
| API. See application
programming interface.
| |||||||||
| Application Programming Interface .
An API defines the calling conventions and other information
needed for one software module (typically an application program)
to utilize the services provided by another software module. MPI
is an API for parallel programming. The term is sometimes used
more loosely to define the notation used by programmers to express
a particular functionality in a program. For example, the OpenMP
specification is referred to as an API. An important aspect of an
API is that any program coded to it can be recompiled to run on
any system that supports that API.
| |||||||||
| Atomic. Atomic
has slightly different meanings in different contexts. An atomic
operation at the hardware level is uninterruptible, for example
load and store, or atomic test-and-set instructions. In the
database world, an atomic operation (or transaction)
is one that appears to execute completely or not at all. In
parallel programming, an atomic operation is one for which
sufficient synchronization has been provided that it cannot be
interfered with by other units of execution. Atomic operations
also must be guaranteed to terminate (e.g. no infinite loops).
| |||||||||
| Autoboxing.
A language feature available in Java 2 1.5 that provides
automatic conversion of data of a primitive type to the
corresponding wrapper type, for example from int to Integer.
| |||||||||
| Bandwidth.
The capacity of a system, usually expressed as ``items per
second''. In parallel computing, the most common usages of the
term bandwidth is in reference to the number of bytes per second
that can be moved across a network link. A parallel program that
generates relatively small numbers of huge messages may be limited
by the bandwidth of the network in which case it is called a
``bandwidth limited'' program. See bisection
bandwidth.
| |||||||||
| Barrier.
A synchronization mechanism applied to groups of units
of execution (UEs), with the property that no UE in the
group may pass the barrier until all UEs in the group have reached
the barrier. In other words, UEs arriving at the barrier suspend
or block until all UEs have arrived; they may then all proceed.
| |||||||||
| Beowulf cluster.
A cluster built from PCs
running the Linux operating system. Clusters
were already well established when Beowulf clusters were first
built in the early 1990s. Prior to Beowulf, however, clusters were
built with workstations running UNIX. By dropping the cost of
cluster hardware, Beowulf clusters dramatically increased access
to cluster computing.
| |||||||||
| Bisection bandwidth.
The bidirectional capacity of a network between two equal-sized
partitions of nodes. The cut across the network is taken at the
narrowest point in each bisection of the network.
| |||||||||
| Broadcast.
Sending a message to all members of a group of recipients, usually
all units of execution participating in a computation.
| |||||||||
| Cache. A
relatively small region of memory that is local to a processor and
is considerably faster than the computer's main memory. Cache
hierarchies consisting of one or more levels of cache are
essential in modern computer systems. Since processors are so much
faster than the computer's main memory, a processor can run at a
significant fraction of full speed only if the data can be loaded
into cache before it is needed and that data can be reused during
a calculation. Data is moved between the cache and the computer's
main memory in small blocks of bytes called cache lines.
An entire cache line is moved when any byte within the memory
mapped to the cache line is accessed. Cache lines are removed from
the cache according to some protocol when the cache becomes full
and space is needed for other data, or when they are accessed by
some other processor. Usually each processor has its own cache
(though sometimes multiple processors share a level of cache), so
keeping the caches coherent (i.e., ensuring that all processors
have the same view of memory through their distinct caches) is an
issue that must be dealt with by computer architects and compiler
writers. Programmers must be aware of caching issues when
optimizing the performance of software.
| |||||||||
| ccNUMA.
Cache-coherent NUMA. A NUMA model where data is coherent at the
level of the cache. See NUMA.
| |||||||||
| Cluster.
Any collection of distinct computers that are connected and used
as a parallel computer, or to form a redundant system for higher
availability. The computers in a cluster are not specialized to
cluster computing and could in principle be used in isolation as
stand alone computers. In other words, the components making up
the cluster, both the computers and the networks connecting them,
are not custom built for use in the cluster. Examples include
Ethernet-connected workstation networks and rack-mounted
workstations dedicated to parallel computing. See workstation
farm.
| |||||||||
| Collective communication.
A high-level operation involving a group of units of execution (UEs)
and having at its core the cooperative exchange of information
between the UEs. The high-level operation may be a pure
communication event (e.g., broadcast)
or it may include some computation (e.g., reduction).
| |||||||||
| Concurrent execution.
A condition in which two or more units of execution (UEs) are
active and making progress simultaneously. This can be either
because they are being executed at the same time on different
processing elements, or because the actions of the UEs are
interleaved on the same processing element.
| |||||||||
| Concurrent program.
Program with multiple loci of control (threads, processes, etc.).
| |||||||||
| Condition variable.
Condition variables are part of the monitor
synchronization mechanism. A condition variable is used by a
process or thread to delay until the monitor's state satisfies
some condition; it is also used to awaken a delayed process when
the condition becomes true. Associated with each condition
variable is a wait set of suspended (delayed)
processes or threads. Operations on a condition variable include wait
(add this process or thread to the wait set for this variable) and
signal or notify (awaken a process or thread on
the wait set for this variable). See monitor.
| |||||||||
| Copy on write.
A technique that ensures, using minimal synchronization, that
concurrent threads will never see a data structure in an
inconsistent state. In order to update the structure, a copy is
made, modifications are made on the copy, and then the reference
to the old structure is atomically replaced with a reference to
the new. This means that a thread holding a reference to the old
structure may continue to access an old (consistent) version, but
no thread will ever see the structure in an inconsistent state.
Synchronization is only needed to acquire and update the reference
to the structure.
| |||||||||
| Counting semaphore.
Counting semaphores are semaphores whose state can represent any
integer. Some implementations allow the P and V
operations to take an integer parameter and increment or decrement
the state (atomically) by that value. See semaphore.
| |||||||||
| Cyclic distribution.
A distribution of data (e.g., components of arrays) or tasks
(e.g., loop iterations) produced by dividing the set into a number
of blocks greater than the number of UEs and then allocating those
blocks to UEs in a cyclic manner analogous to dealing a deck of
cards.
| |||||||||
| Data parallel.
A type of parallel computing in which the concurrency is expressed
by applying a single stream of instructions simultaneously to the
elements of a data structure.
| |||||||||
| Deadlock.
An error condition common in parallel programming in which the
computation has stalled because a group of UEs are blocked and
waiting for each other in a cyclic configuration.
| |||||||||
| Design pattern.
A design pattern is a ``solution to a problem in context''; that
is, it represents a high-quality solution to a recurring problem
in design.
| |||||||||
| Distributed computing.
A type of computing in which a computational task is divided into
subtasks that execute on a collection of networked computers. The
networks are general-purpose networks (LANs, WANs, or the
Internet) as opposed to dedicated cluster interconnects.
| |||||||||
| Distributed shared memory.
A computer system that constructs an address space
shared among multiple UEs from physical memory subsystems that are
distinct and distributed about the system. There may be
operating-system and hardware support for the distributed shared
memory system, or the shared memory may be implemented entirely in
software as a separate middleware layer (see Virtual
shared memory.)
| |||||||||
| DSM. See distributed
shared memory.
| |||||||||
| Eager evaluation.
A scheduling strategy where the evaluation of an expression, or
execution of a procedure may occur as soon as (but not before) all
of its arguments have been evaluated. Eager evaluation is typical
for most programming environments and contrasts with lazy
evaluation. Eager evaluation can sometimes lead to extra
work (or even non-termination) when an argument that will not
actually be needed in a computation must be computed anyway.
| |||||||||
| Efficiency.
The efficiency E of a computation is the speedup
normalized by the number of PEs (P). It is given by
and indicates how effectively the resources in a parallel computer are used.
| |||||||||
| Embarrassingly parallel.
A task-parallel algorithm in which the tasks are completely
independent. See the Task Parallelism
pattern.
| |||||||||
| Explicitly parallel language.
A parallel programming language in which the programmer fully
defines the concurrency and how it will be exploited in a parallel
computation. OpenMP, Java, and MPI are explicitly parallel
languages.
| |||||||||
| Factory.
Factory corresponds to design patterns described in [GHJV95]
and is implemented using a class that can return an instance of
one of several subclasses of an abstract base class.
| |||||||||
| False sharing.
False sharing occurs when two semantically independent variables
reside in the same cache line and UEs running on multiple
processors modify these variables. They are semantically
independent so memory conflicts are avoided, but the cache line
holding the variables must be shuffled between the processors and
the performance suffers.
| |||||||||
| Fork. See fork/join.
| |||||||||
| Fork/join.
A programming model used in multithreaded APIs such as OpenMP.
A thread executes a fork and creates additional threads.
The collection of threads (called a team in OpenMP) execute
concurrently. When the members of the team complete their
concurrent tasks they execute joins and suspend until every
member of the team has arrived at the join. At that point, the
members of the team are destroyed and the original thread
continues.
| |||||||||
| Framework.
A reusable partially complete program that embodies a design for
applications in a particular domain. Programmers complete the
program by providing application-specific components.
| |||||||||
| Future variable.
A mechanism used in some parallel programming enviroments for
coordinating the execution of UEs. The future variable is a
special variable that will eventually hold the result from an
asynchronous computation. For example, Java (in package java.util.concurrent)
contains a class Future to hold future variables.
| |||||||||
| Generics.
Programming language features which allow programs to contain
placeholders for certain entities, typically types. The generic
component's definition is completed before it is used in a
program. Generics are included in Ada, C++ (via templates), and
Java.
| |||||||||
| Grid. A
grid is an architecture for distributed computing and resource
sharing. A grid system is composed of a heterogeneous collection
of resources connected by local-area and/or wide-area networks
(often the Internet). These individual resources are general and
include compute servers, storage, application servers, information
services, or even scientific instruments. Grids are often
implemented in terms of Web services and integrated middleware
components that provide a consistent interface to the grid. A grid is different from a cluster in that the resources in a
grid are not controlled through a single point of administration;
the grid middleware manages the system so control of resources on
the grid and the policies governing use of the resources remain
with the resource owners.
| |||||||||
| Heterogeneous.
A heterogeneous system is constructed from components of more than
one kind. An example is a distributed system with a variety of
processor types.
| |||||||||
| Homogeneous.
The components of a homogeneous system are all of the same kind.
| |||||||||
| Hypercube.
A multicomputer in which the nodes are placed
at the vertices of a d-dimensional cube. The most
frequently used configuration is a binary hypercube
where each of 2n nodes is connected to n others.
| |||||||||
| Implicitly parallel language.
A parallel programming language in which the details of what can
execute concurrently and how that concurrency is implemented is
left to the compiler. Most parallel functional
and dataflow languages are implicitly parallel.
| |||||||||
| Incremental parallelism.
Incremental parallelism is a technique for parallelizing an
existing program, in which the parallelization is introduced as a
sequence of incremental changes, parallelizing one loop at a time.
Following each transformation the program is tested to ensure that
its behavior is the same as the original program, greatly
decreasing the changes of introducing undetected bugs. See refactoring.
| |||||||||
| Java Virtual Machine.
The Java Virtual Machine, or JVM, is an abstract stack-based
computing machine whose instruction set is called Java bytecode.
Typically, Java programs are compiled into class files containing
Java Byte Code. The purpose of the JVM is to provide a consistent
execution platform regardless of the underlying hardware.
| |||||||||
| Join. See fork/join.
| |||||||||
| JVM. See Java
Virtual Machine.
| |||||||||
| Latency.
The fixed cost of servicing a request such as sending a message or
accessing information from a disk. In parallel computing, the term
most often is used to refer to the time it takes to send an empty
message over the communication medium, from the time the send
routine is called to the time the empty message is received by the
recipient. Programs that generate large numbers of small messages
are sensitive to the latency and are called latency bound
programs.
| |||||||||
| Lazy evaluation.
A scheduling policy that does not evaluate an expression (or
invoke a procedure) until the results of the evaluation are
needed. Lazy evaluation may avoid some unnecessary work and in
some situations may allow a computation to terminate that
otherwise would not. Lazy evaluation is often used in functional
and logic programming.
| |||||||||
| Linda. A
coordination language for parallel programming.
See tuple space.
| |||||||||
| Load balance.
In a parallel computation, tasks are assigned to UEs which are
then mapped onto PEs for execution. The net work carried out by
the collection of PEs is the ``load'' associated with the
computation. ``Load balance'' refers to how that load is
distributed among the PEs. In an efficient parallel program, the
load is balanced so each PE spends about the same amount of time
on the computation. In other words, in a program with a good load
balance, each PE finishes with its share of the load at about the
same time.
| |||||||||
| Load balancing.
The process of distributing work to UEs such that each UE involved
in a parallel computation takes approximately the same amount of
time. There are two major forms of load balancing. In static
balancing the distribution of work is determined before the
computation starts. In dynamic load balancing, the load is
modified as the computation proceeds (i.e., during runtime).
| |||||||||
| Locality.
The extent to which the computations carried out by a processing
element use data that is associated with (i.e., is close to)
that processing element. For example, in many dense linear algebra
problems, the key to high performance is to decompose matrices
into blocks and then structure the calculations in terms of these
blocks so data brought into a processor's cache
is used many times. This is an example of an algorithm
transformation that increases locality in a computation.
| |||||||||
| Massively parallel processor.
A distributed-memory parallel computer designed to scale to
hundreds if not thousands of processors. To better support high
scalability, the computer elements or nodes in the MPP
machine are custom-designed for use in a scalable computer. This
typically includes tight integration between the computing
elements and the scalable network.
| |||||||||
| Message Passing Interface.
A standard message-passing interface adopted by most MPP
vendors as well as by the cluster-computing community. The
existence of a widely-supported standard enhances program
portability; an MPI-based program developed for one platform
should also run on any other platform for which an implementation
of MPI exists.
| |||||||||
| MIMD.
Multiple Instruction, Multiple Data. One of the categories of
architectures in Flynn's taxonomy of computer
architectures. In a MIMD system, each processing element has its
own stream of instructions operating on its own data. The vast
majority of modern parallel systems use the MIMD architecture.
| |||||||||
| Monitor.
Monitors are a synchronization mechanism originally proposed by
Hoare [Hoa74].
A monitor is an abstract data type implementation that guarantees
mutually exclusive access to its internal data. Conditional
synchronization is provided by condition variables
(see condition
variables).
| |||||||||
| MPI. See Message
Passing Interface.
| |||||||||
| MPP. See massively
parallel processor.
| |||||||||
| Multicomputer.
A parallel computer based on a distributed-memory, MIMD parallel
architecture. The system appears to the user as a single computer.
| |||||||||
| Multiprocessor.
A parallel computer with multiple processors that share an address
space.
| |||||||||
| Mutex. A
mutual exclusion lock. A mutex serializes the
execution of multiple threads.
| |||||||||
| Node.
Common term for the computational elements that make up a
distributed-memory parallel machine. Each node has its own memory
and at least one processor; that is, a node can be a uniprocessor
or some type of multiprocessor.
| |||||||||
| NUMA.
Non-Uniform Memory Access. This term is used to describe a
shared-memory computer containing a hierarchy of memories, with
different access times for each level in the hierarchy. The
distinguishing feature is that the time required to access memory
locations is not uniform; i.e., access times to different
locations can be different.
| |||||||||
| OpenMP.
A specification defining compiler directives, library routines,
and environment variables that can be used to denote shared-memory
parallelism in Fortran and C/C++ programs. OpenMP implementations
exist for a large variety of platforms.
| |||||||||
| OR parallelism.
An execution technique in parallel logic languages
in which multiple clauses may be evaluated in parallel. For
example, consider a problem with two clauses A: B,C and A:
E,F. The clauses can execute in parallel until one of them
succeeds.
| |||||||||
| Parallel file system.
A file system that is visible to any processor in the system and
can be read and written by multiple UEs simultaneously. Although a
parallel file system appears to the computer system as a single
file system, it is physically distributed among a number of disks.
To be effective, the aggregate throughput for read and write must
be scalable.
| |||||||||
| Parallel overhead.
The time spent in a parallel computation managing the computation
rather than computing results. Contributors to parallel overhead
include thread creation and scheduling, communication, and
synchronization.
| |||||||||
| PE. See processing
element.
| |||||||||
| Peer-to-peer computing.
A distributed computing model in which each node has equal
standing among the collection of nodes. In the most typical usage
of this term, the same capabilities are offered by each node and
any node can initiate a communication session with another node.
This contrasts with, for example, client/server computing.
The capabilities that are shared in peer-to-peer computing include
file sharing as well as computation.
| |||||||||
| POSIX.
The ``Portable Operating System Interface'' as defined by the
Portable Applications Standards Committee (PASC) of the IEEE
Computer Society. While other operating systems follow some of the
POSIX standards, the primary use of this term refers to the family
of standards that define the interfaces in UNIX and UNIX-like
(e.g., Linux) operating systems.
| |||||||||
| Precedence graph.
A way of representing the order constraints among a collection of
statements. The nodes of the graph represent the statements, and
there is a directed edge from node A to node B if statement A must
be executed before statement B. A precedence graph with a cycle
represents a collection of statements that cannot be executed
without deadlock.
| |||||||||
| Process.
A collection of resources that enable the execution of program
instructions. These resources can include virtual memory, I/O
descriptors, a runtime stack, signal handlers, user and group IDs,
and access control tokens. A more high-level view is that a
process is a ``heavyweight'' unit of execution with its own
address space.
| |||||||||
| Process migration.
Changing the processor responsible for running a process during
execution. Process migration is commonly used to dynamically
balance the load on multiprocessor systems. It
is also used to support fault-tolerant computing
by moving processes away from failing processors.
| |||||||||
| Processing element.
A generic term used to reference a hardware element that executes
a stream of instructions. The context defines what unit of
hardware is considered a processing element. Consider a cluster of
SMP workstations. In some programming environments, each
workstation is viewed as executing a single instruction stream; in
this case, a processing element is a workstation. A different
programming environment running on the same hardware, however, may
view each processor of
the individual workstations as executing an individual instruction
stream; in this case, the processing element is the processor
rather than the workstation.
| |||||||||
| Programming environment.
Programming environments provide the basic tools and application
programming interfaces, or APIs, needed to construct
programs. A programming environment implies a particular
abstraction of the computer system called a programming
model.
| |||||||||
| Programming model.
Abstraction of a computer system, for example the ``von Neumann
model'' used in traditional sequential computers. For parallel
computing, there are many possible models typically reflecting
different ways processors can be interconnected. The most common
are based on shared memory, distributed memory with message
passing, or a hybrid of the two.
| |||||||||
| Pthreads.
An abbreviation for POSIX threads; i.e., the definition of threads
in the various POSIX standards. See POSIX.
| |||||||||
| PVM.
Parallel Virtual Machine. A message-passing
library for parallel computing. PVM played an important role in
the history of parallel computing as it was the first portable
message-passing programming environment to gain widespread use in
the parallel computing community. It has largely been superseded
by MPI.
| |||||||||
| Race condition.
An error condition peculiar to parallel programs in which the
outcome of a program changes as the relative scheduling of UEs
varies.
| |||||||||
| Reader/writer locks.
This pair of locks is similar to mutexes except that multiple UEs
may hold a read lock while a write lock excludes both other
writers and all readers. Reader/writer locks are often effective
when resources protected by the lock are read far more often than
they are written.
| |||||||||
| Reduction.
An operation that takes a collection of objects (usually one on
each UE) and combines them into a single object on one UE or
combines them such that each UE has a copy of the combined object.
Reductions typically involve combining a set of values pairwise
using an associative, commutative operator such as addition or max.
| |||||||||
| Refactoring.
Refactoring is a software engineering technique where a program is
restructured carefully so as to alter its internal structure
without changing its external behavior. The restructuring occurs
through a series of small transformations (called ``refactorings'')
that can be verified as ``behavior preserving'' following each
transformation. The system is fully working and verifiable
following each transformation, greatly decreasing the chances of
introducing serious, undetected bugs. Incremental parallelism can
be viewed as an application of refactoring to parallel
programming. See incremental
parallelism.
| |||||||||
| Remote procedure call.
A procedure invoked in a different address space than the caller,
often on a different machine. Remote procedure calls are a popular
approach for interprocess communication and launching remote
processes in distributed client-server computing environments.
| |||||||||
| RPC. See remote
procedure call.
| |||||||||
| Semaphore.
An abstract data type used to implement certain kinds of
synchronization. A semaphore has the following characteristics: A
semaphore has a value that is constrained to be a non-negative
integer and two atomic operations. The allowable operations
are V (sometimes called up) and P
(sometimes called down). A V operation increases
the value of the semaphore by one. A P operation
decreases the value of the semaphore by one, provided that can be
done without violating the constraint that the value be
non-negative. A P operation that is initiated when the
value of the semaphore is 0 suspends. It may continue when the
value is positive).
| |||||||||
Serial fraction.
Most computations consist of parts that contain exploitable
concurrency and parts that must be executed serially. The serial
fraction is that fraction of the program's execution time
taken up by the parts that must execute serially. For example, if
a program decomposes into setup, compute, and finalization,
we could write
If the setup and finalization phases must execute serially, then the serial fraction would be
|
| Shared address space.
An addressable block of memory that is shared between a collection
of UEs.
| |||||||||||||
| Shared memory.
A term applied to both hardware and software indicating the
presence of a memory region that is shared between system
components. For programming environments, the term means that
memory is shared between processes or threads. Applied to
hardware, it means that the architectural feature tying processors
together is shared memory. See shared
address space.
| |||||||||||||
| Shared nothing.
A distributed-memory MIMD architecture where nothing other than
the local area network is shared between the nodes.
| |||||||||||||
| Simultaneous multithreading.
Simultaneous multithreading is an architectural feature of some
processors that allows multiple threads to issue instructions on
each cycle. In other words, SMT allows the functional units that
make up the processor to work on behalf of more than one thread at
the same time. Examples of systems utilizing SMT are
microprocessors from Intel Corporation that use Hyper-Threading
Technology.
| |||||||||||||
| SIMD.
Single Instruction, Multiple Data. One of the categories in
Flynn's taxonomy of computer architectures. In
a SIMD system, a single instruction stream runs synchronously on
multiple processors, each with its own data stream.
| |||||||||||||
| Single-assignment variable.
A special kind of variable to which a value can be assigned only
once. The variable initially is in an unassigned state. Once a
value has been assigned, it cannot be changed. These variables are
commonly used with programming environments that employ a dataflow
control strategy, with tasks waiting to fire until all input
variables have been assigned.
| |||||||||||||
| SMP. See symmetric
multiprocessor.
| |||||||||||||
| SMT. See simultaneous
multithreading.
| |||||||||||||
| Speedup.
Speedup, S, is a multiplier indicating how many times
faster the parallel program is than its sequential counterpart. It
is given by
where T(n) is the total execution time on a system with n processing elements. When the speedup equals the number of PEs in the parallel computer, the speedup is said to be perfectly linear.
| |||||||||||||
| Single Program Multiple Data.
This is the most common way to organize a parallel program,
especially on MIMD
computers. The idea is that a single program is written and loaded
onto each node of a parallel computer. Each copy of the single
program runs independently (aside from coordination events), so
the instruction streams executed on each node can be completely
different. The specific path through the code is in part selected
by the node ID.
| |||||||||||||
| SPMD. See single
program multiple data.
| |||||||||||||
| Stride.
The increment used when stepping through a structure in memory.
The precise meaning of stride is context dependent. For example,
in an
M×N array stored in a column-major order in a
contiguous block of memory, traversing the elements of a column of
the matrix involves a stride of one. In the same example,
traversing across a row requires a stride of M.
| |||||||||||||
| Symmetric multiprocessor.
A shared-memory computer in which every processor is functionally
identical and has ``equal-time'' access to every memory address.
In other words, both memory addresses and OS services are equally
available to every processor.
| |||||||||||||
| Synchronization.
Enforcing constraints on the ordering of events occurring in
different UEs. This is primarily used to ensure that shared
resources are accessed by a collection of UEs in such a way that
the program is correct regardless of how the UEs are scheduled.
| |||||||||||||
| Systolic array.
A parallel architecture consisting of an array of processors with
each processor connected to a small number of its nearest
neighbors. Data flows through the array. As data arrives at a
processor, it carries out its assigned operations and then passes
the output to its one or more of its nearest neighbors. While each
processor in a systolic array can run a distinct stream of
instruction, they progress in ``lock-step'' alternating between
computation and communication phases. Hence, systolic arrays have
a great deal in common with the SIMD architecture.
| |||||||||||||
| Systolic algorithm.
A parallel algorithm where tasks operate synchronously with a
regular nearest-neighbor communication pattern. Many computational
problems can be formulated as systolic algorithms by reformulating
as a certain type of recurrence relation.
| |||||||||||||
| Task. This
term can have several meanings, depending on context. We use it to
mean a sequence of operations that together make up some logical
part of an algorithm or program.
| |||||||||||||
| Task queue.
A queue that holds tasks for execution by one or more UEs. Task
queues are commonly used to implement dynamic scheduling
algorithms in Task Parallelism
algorithms,
particularly when used with the Master/Worker.
| |||||||||||||
| Thread.
A fundamental unit of execution on certain computers. In a UNIX
context, threads are associated with a process and share the
process's environment. This makes the threads lightweight
(i.e., a context switch between threads is cheap). A more
high-level view is that a thread is a ``lightweight'' unit of
execution that shares an address space with other threads. See unit
of execution, process.
| |||||||||||||
| Transputer.
The transputer is a microprocessor developed by Inmos Ltd. with
on-chip support for parallel processing. Each processor contains
four high-speed communication links that are easily connected to
the links of other transputers and a very efficient built-in
scheduler for multiprocessing.
| |||||||||||||
Tuple space.
A shared-memory system where the elements held in the memory are
compound objects known as tuples. A tuple is a small set of
fields holding values or variables, as in the following examples.
As seen in these examples, the fields making up a tuple can hold integers, strings, variables, arrays, or any other value defined in the base programming language. While traditional memory systems access objects through an address, tuples are accessed by association. The programmer working with a tuple space defines a template and asks the system to deliver tuples matching the template. Tuple spaces were created as part of the Linda coordination language [CG91]. The Linda language is small, with only a handful of primitives to insert tuples, remove tuples, and fetch a copy of a tuple. It is combined with a base language such as C, C++, or Fortran to create a combined parallel programming language. In addition to its original implementations on machines with a shared address space, Linda was also implemented with a virtual shared memory and used to communicate between UEs running on the nodes of distributed-memory computers. The idea of an associative virtual shared memory inspired by Linda has been incorporated into JavaSpaces [FHA99].
| |||||||||||||
| UE. See unit
of execution.
| |||||||||||||
| Unit of execution.
Generic term for one of a collection of concurrently-executing
entities, usually either processes or threads. See process,
thread.
| |||||||||||||
| Vector supercomputer.
A supercomputer with a vector hardware unit as an integral part of
its central processing unit boards. The vector hardware processes
arrays in a pipeline fashion.
| |||||||||||||
| Virtual shared memory.
A system that provides the abstraction of shared memory, allowing
programmers to write to a shared memory even when the underlying
hardware is based on a distributed-memory architecture. Virtual
shared memory systems can be implemented within the operating
system or as part of the programming environment.
| |||||||||||||
| Workstation farm. A cluster constructed from workstations typically running some version of UNIX. In some cases, the term ``farm'' is used to imply that the system will be utilized to run large numbers of independent sequential jobs as opposed to parallel computing. |
![]()
31 March, 2005