|
Pattern Name: ChooseStructure |
AlgorithmStructure Design Space |
This pattern will guide the algorithm designer to the AlgorithmStructure patterns most appropriate for the problem.
Once you have decomposed your problem to find the exploitable concurrency, you need to refine the design into an algorithm that can run on a parallel computer. As discussed earlier (in the Introduction pattern for this design space), to accomplish this goal you need to find an algorithm structure that maps the concurrency (i.e., the tasks, ordered task groups, task-local data, and shared data) onto the units of execution that run on a parallel computer.
Of the countless ways to define an algorithm structure, most follow one of nine basic design patterns. The key issue is to decide which pattern is most appropriate for your problem.
For example, consider the medical imaging problem described earlier in the FindingConcurrency Introduction pattern. This application simulates a large number of gamma rays as they move through a body and out to a camera. One way to describe the concurrency is to define the simulation of each ray as a task. Since they are all logically equivalent, we put them into a single task group. The only data shared between the tasks are read-only accesses to a large data structure representing the body. Hence the tasks do not depend on each other.
Thus, the only issue we need to worry about as we select an algorithm structure is how these independent tasks are mapped onto units of execution (UEs). In other words, the way tasks are mapped onto the UEs is the major organizing principle that we will use as we select which algorithm structure to use. Using the procedures described in this pattern, we'll see that the structure appropriate to this problem is the one described by the EmbarrassinglyParallel pattern.
This process -- looking at a problem's concurrency, identifying the major organizing principle, and then finding the appropriate algorithm structure -- is the problem addressed by this design pattern.
This pattern is used after you have found the concurrency in your problem (using the patterns of the FindingConcurrency design space).
The analysis contained in this pattern breaks down into three topics:
A good algorithm design must strike a balance between two opposing forces. One force tries to keep it abstract and able to map onto any parallel computer. The other force pushes it to fit the needs of a specific target architecture. The challenge faced by the designer, especially at this early phase of the algorithm design, is to leave the parallel algorithm design abstract enough to support portability while ensuring that it will support the parallel systems most important to you.
At this point in the design of our parallel algorithm, we have (1) a number of tasks, (2) an understanding of how the problem's data is decomposed onto and shared between the tasks, and (3) an ordering of task groups to express temporal or other constraints between the tasks. To refine the design further and move it closer to a program that can execute these tasks concurrently, we need to map the concurrency onto multiple units of execution (UEs). There are three major steps in this refinement.
What constraints are placed on your design by the target computer and its supporting programming environments? This is tricky, since you want to keep your program as portable as possible. In an ideal world, it wouldn't be necessary to consider such questions at this stage of the design. This is not an ideal world, however, and you need to consider the major features of your target platform.
The primary issue is how many UEs your system will effectively support. An algorithm that works well for ten UEs may not work well at all for hundreds of UEs. You don't want to decide on a specific number (in fact to do so would overly constrain the applicability of your design), but you do need to decide on an order-of-magnitude number of UEs.
Another issue is the way information is shared between UEs. How expensive is it to share information between UEs? If there is hardware support for shared memory, information exchange takes place through shared access to common memory, and frequent data sharing makes sense. On the other hand, if the target is a collection of nodes with a slow network, sharing information is very expensive, and your parallel algorithm must avoid communication wherever possible.
When thinking about both of these issues -- the number of UEs and the cost of sharing information -- avoid the tendency to over-constrain your design. Software usually outlives hardware, so over the course of a program's life, you may need to support a tremendous range of target platforms. You want your algorithm to meet the needs of your target platform, but at the same time, you want to keep it flexible so it can adapt to different classes of hardware.
Also, remember that in addition to multiple UEs and some way to share information between them, a parallel computer has one or more programming environments to use when you code your parallel algorithm. Do you know which parallel programming environment you will use for coding your algorithm? If so, what does this imply about how tasks are created and how information is shared between UEs?
Consider the concurrency you found in the FindingConcurrency design space. It consists of tasks and groups of tasks, data (both shared and task-local), and ordering constraints between task groups. We need to find an algorithm structure that represents how this concurrency maps onto the UEs. The first step is to find the major organizing principle implied by the concurrency. This usually falls into one of three camps: "organization by orderings", "organization by tasks", or "organization by data". Algorithms in the first two groups are task-parallel, since the design is guided by how the computation is decomposed into tasks. Algorithms in the third group are data-parallel, because how the data is decomposed guides the algorithm. We now consider each of these in more detail.
For some problems, the major feature of the concurrency is the presence of well-defined interacting groups of tasks, and the key issue is how these groups are ordered with respect to each other. For example, a GUI-driven program might be parallelized by decomposing it into a task that accepts user input, a task that displays output, and one or more background computational tasks, with the tasks interacting via "events" (e.g., the user does something, or a part of the background computation completes). Here the major feature of the concurrency is the way in which these distinct task groups interact.
For other problems, there is really only one group of tasks active at one time, and the way the tasks within this group interact is the major feature of the concurrency. Examples include so-called "embarrassingly parallel" programs in which the tasks are completely independent, as well as programs in which the tasks in a single group cooperate to compute a result.
Finally, for some problems, the way data is decomposed and shared between tasks stands out as the major way to organize the concurrency. For example, many problems focus on the update of a few large data structures, and how this structure is decomposed and distributed among UEs may be the most productive way to think about the concurrency. Programs to solve differential equations or perform linear algebra often fall into this category, since they frequently are based on updating large data structures.
As you think about your problem and search for the most productive way to begin organizing your concurrency and mapping it onto UEs, remember that the most effective parallel algorithm design may be hierarchical or compositional: It often happens that the very top level of the design is a sequential composition of one or more AlgorithmStructure patterns (for example, a loop whose body is an instance of an AlgorithmStructure pattern). Other designs may be organized hierarchically, with one pattern used to organize the interaction of the major task groups and other patterns used to organize tasks within the groups.
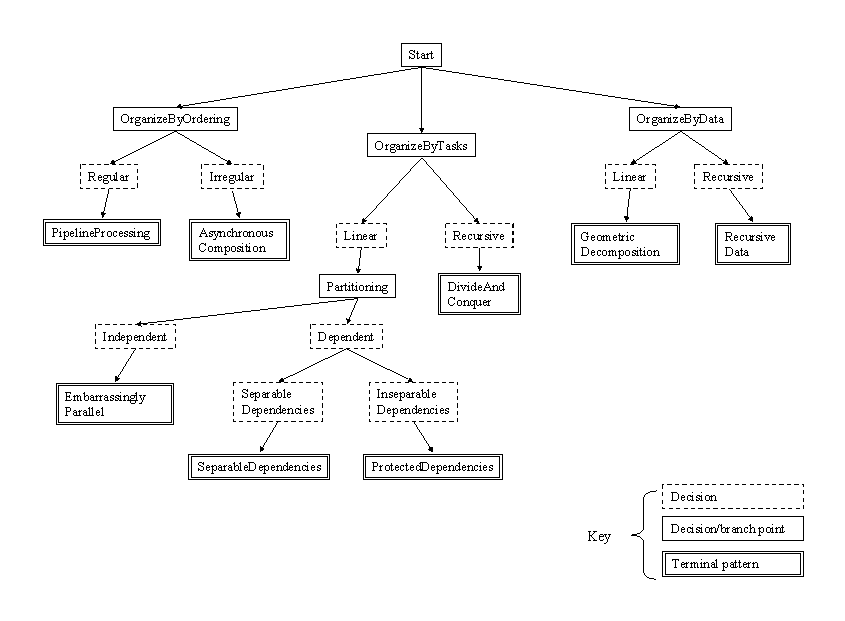
We are now ready to actually select an algorithm structure. We do this with an understanding of constraints from our target platform, an appreciation of the role of hierarchy and composition, and a major organizing principle for our problem. To guide us through this selection, we use the decision tree presented in the following figure:
Starting at the top of the tree, consider your concurrency and the major organizing principle, and use this information to select one of the three branches of the tree. Then follow the discussion below for the appropriate subtree.
The first subtree should be selected when the major organizing principle is how the groups of tasks are ordered with respect to each other. This pattern group has two members, reflecting two ways task groups can be ordered. One choice represents "regular" orderings that do not change during the algorithm; the other represents "irregular" orderings that are more dynamic and unpredictable.
The second subtree is for problems in which the execution of the tasks themselves is the best organizing principle. There are many ways to work with such "task-parallel" problems, making this the largest group of patterns. The first decision to make is how the tasks are enumerated. If they can be gathered into a set linear in any number of dimensions, then we take the Partitioning branch. If the tasks are enumerated by a recursive procedure, than we take the Tree branch.
If the partitioning branch is selected, the next question is to consider the dependencies between the tasks. If there are no dependencies between the tasks (i.e., the tasks do not need to exchange information), then you can use the following pattern for your algorithm structure:
If there are dependencies between the tasks, we need to decide how they can be resolved. For a large class of problems, the dependencies are expressed by write-once updates or associative accumulation into shared data structures. In these cases, the dependencies are separable and we get the following algorithm structure:
If the dependencies involve true information-sharing between concurrent tasks, however, you can't use a trick to make the concurrency look like the simple embarrassingly parallel case. There is no way to get around explicitly managing the shared information between tasks, and we get the ProtectedDependencies pattern:
This completes the Partitioning branch; now consider the patterns in the Tree branch. Here we have two cases. These cases are very similar, differing in how the subproblems are solved once the tasks have been recursively generated:
The third and final subtree corresponds to patterns for which the decomposition of the data is the major organizing principle in understanding the concurrency. There are two patterns in this group, differing in how the decomposition is structured -- linearly in each dimension or recursively.
Consider the medical imaging problem described in the FindingConcurrency TaskDecomposition pattern. We showed how the problem could be viewed in terms of the set of concurrently executing tasks. This suggests that the major organizing principle is the way the tasks are organized, so we start by following the "Organize By Tasks" branch.
We now consider the nature of our set of tasks. Are the tasks arranged hierarchically? Or do the tasks reside in an unstructured or flat set? For our medical imaging problem, the tasks are in an unstructured set with no obvious hierarchical structure between them. Hence, we follow the Partitioning branch of the decision tree.
The next decision takes into account the dependencies between the tasks. For this example, the tasks are independent. This implies that the algorithm structure to use for this problem is described in the EmbarrassinglyParallel pattern. Note that an embarrassingly parallel algorithm should not be viewed as trivial to implement. Plenty of careful design work is needed to come up with a correct program that efficiently schedules the set of independent tasks for execution on the UEs.